
What is a Snowflake Virtual Warehouse?
Updated: September 4th 2020

Virtual Warehouse in Snowflake - Explained
A virtual warehouse on Snowflake is a cluster of database servers deployed on-demand to execute user queries. On a traditional on-premises database, this would be an MPP server (Massively Parallel Processing), which is a fixed hardware deployment. However, on Snowflake, a Virtual Warehouse is a dynamically allocated cluster of database servers consisting of CPU cores, memory, and SSD, maintained in a hardware pool and deployed within milliseconds. To the end-user, this process is entirely transparent.
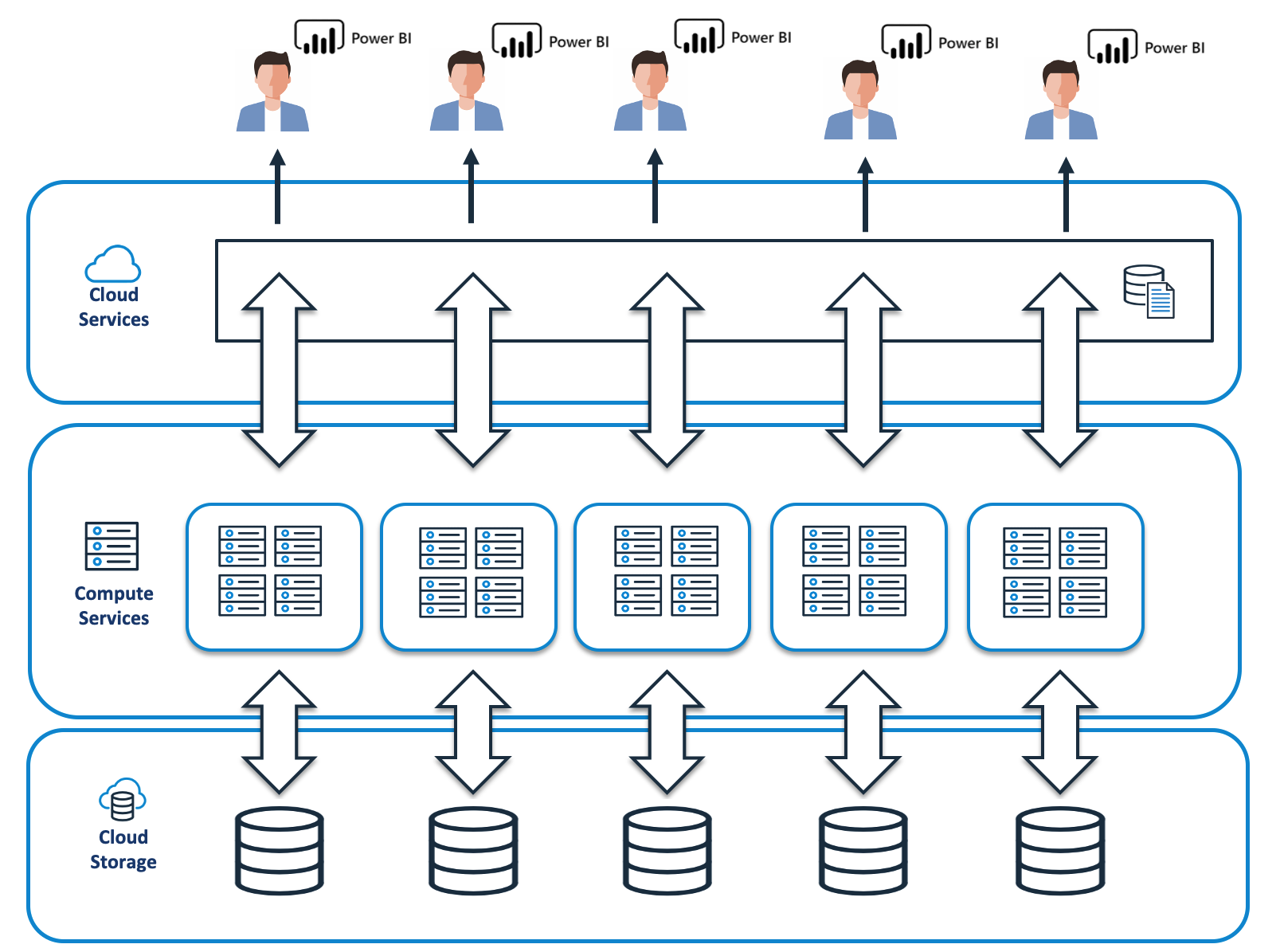
The diagram below shows the Snowflake architecture and how a Virtual Warehouse provides the compute services for Snowflake and is coordinated by the Cloud Services layer.
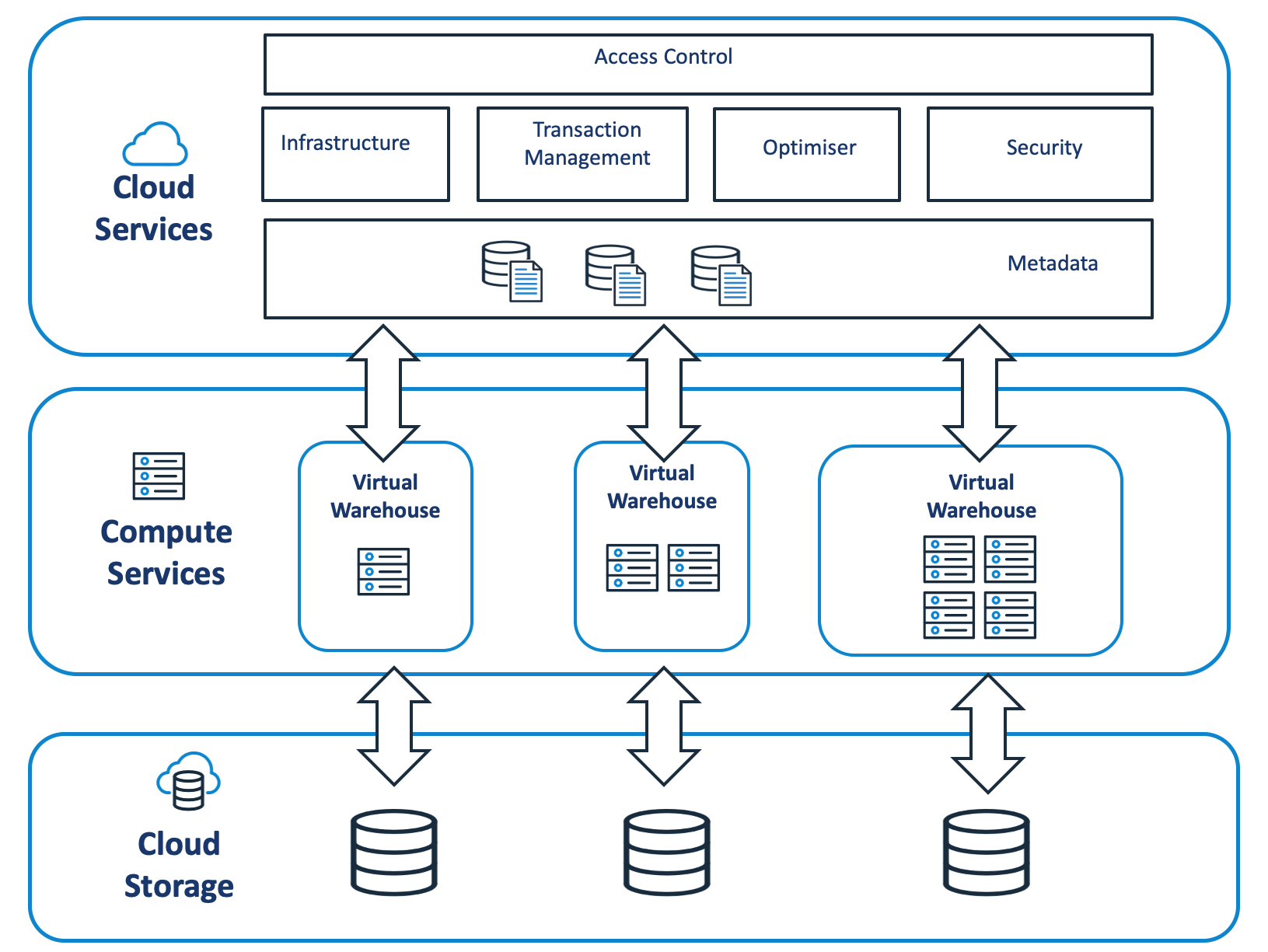
Snowflake System Architecture
When users connect to Snowflake, they always connect via a URL that runs a process in the Cloud Services layer. Any SQL which needs access to data is executed on a virtual warehouse and data retrieved from Cloud Storage.
The architecture above is unique, and has the following advantages:
Elastic Sizing: Because the storage and compute hardware is entirely independent, and the fast SSD storage in the virtual warehouse is altogether temporary, it is possible to allocate a range of virtual warehouse sizes and adjust these on-the-fly as needed. This means it’s possible to start with a single server XSMALL and change this within milliseconds to a 64 server 3XLARGE monster machine.
Zero Contention: Any number of virtual warehouses can be deployed (each sized to the particular demands of the task), and each is entirely independent of the others. This leads to zero contention for resources compared to traditional database architecture, where multiple groups share the same machine resources. With a Snowflake Virtual Warehouse, each team has dedicated hardware.
Automatic Suspend and Resume: When queries are no longer running on a virtual warehouse, it can automatically suspend and then resume within milliseconds when new SQL is executed. The entire process is transparent to the end-user.
Per Second Pay-as-you-go. Unlike other cloud-based services that charge for a machine for an hour, Snowflake charges per-second after the first minute. This means you pay only for the compute resources you consume.
What is a Virtual Warehouse?
As Snowflake is provided as a managed service, they take great pains to avoid describing the technical details, and the Virtual Warehouse details are no different. Snowflake does not provide details, but the diagram below illustrates the internal architecture.
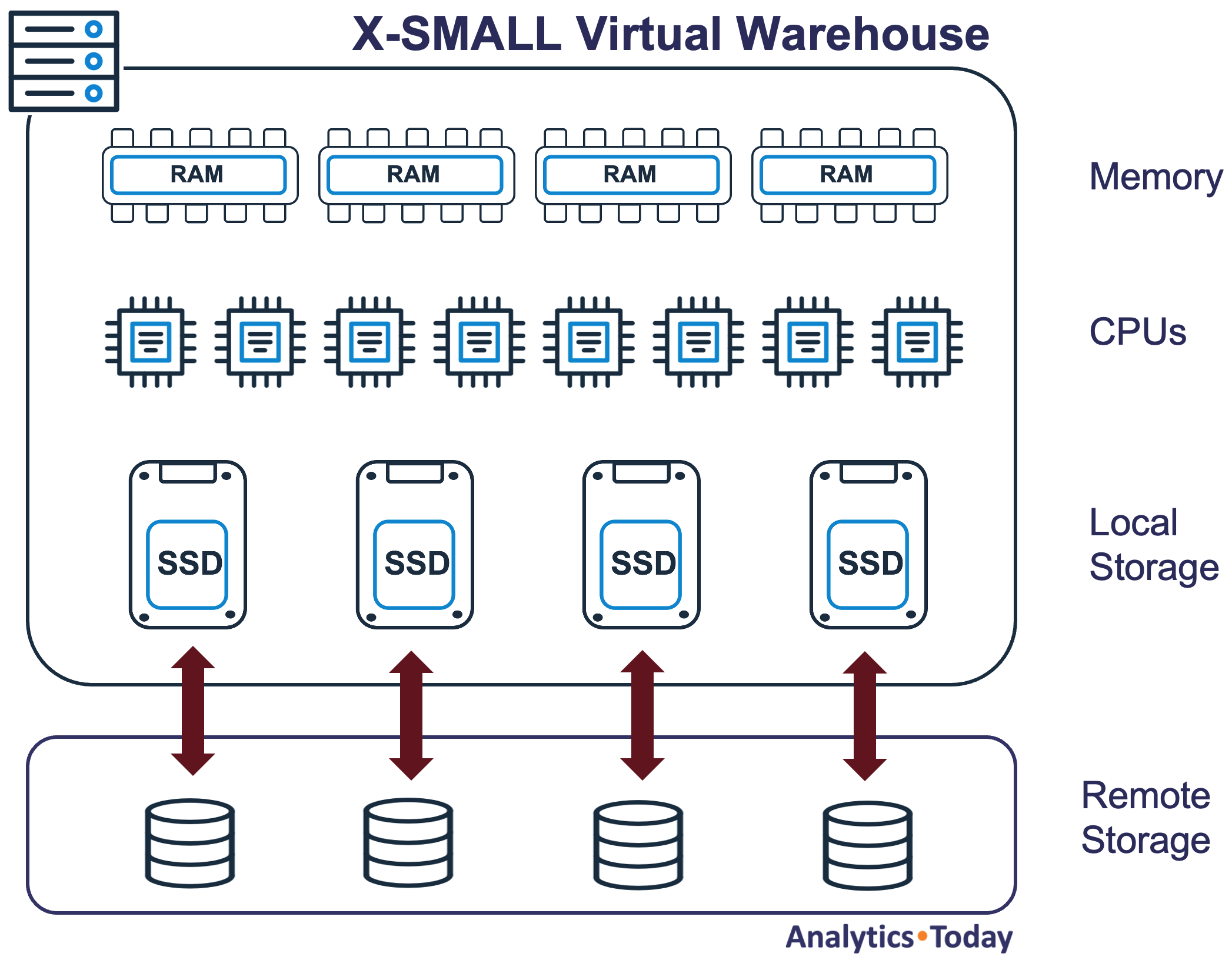
As the diagram above illustrates, a Virtual Warehouse consists of several servers, and each server is a computer with (currently) eight virtual CPUs, memory and SSD storage. When a query is executed, data is read from Remote Storage into Local Storage (SSD), acting as a data cache.
When created, a Virtual Warehouse comprises a cluster of servers that work together as a single machine and are sized as simple T-Shirt sizes.
Warehouse Sizes
The table below shows the Snowflake warehouse sizes, which start at an XSMALL, which has a single node, right up to the gigantic X6LARGE machine which is over 500 times larger.
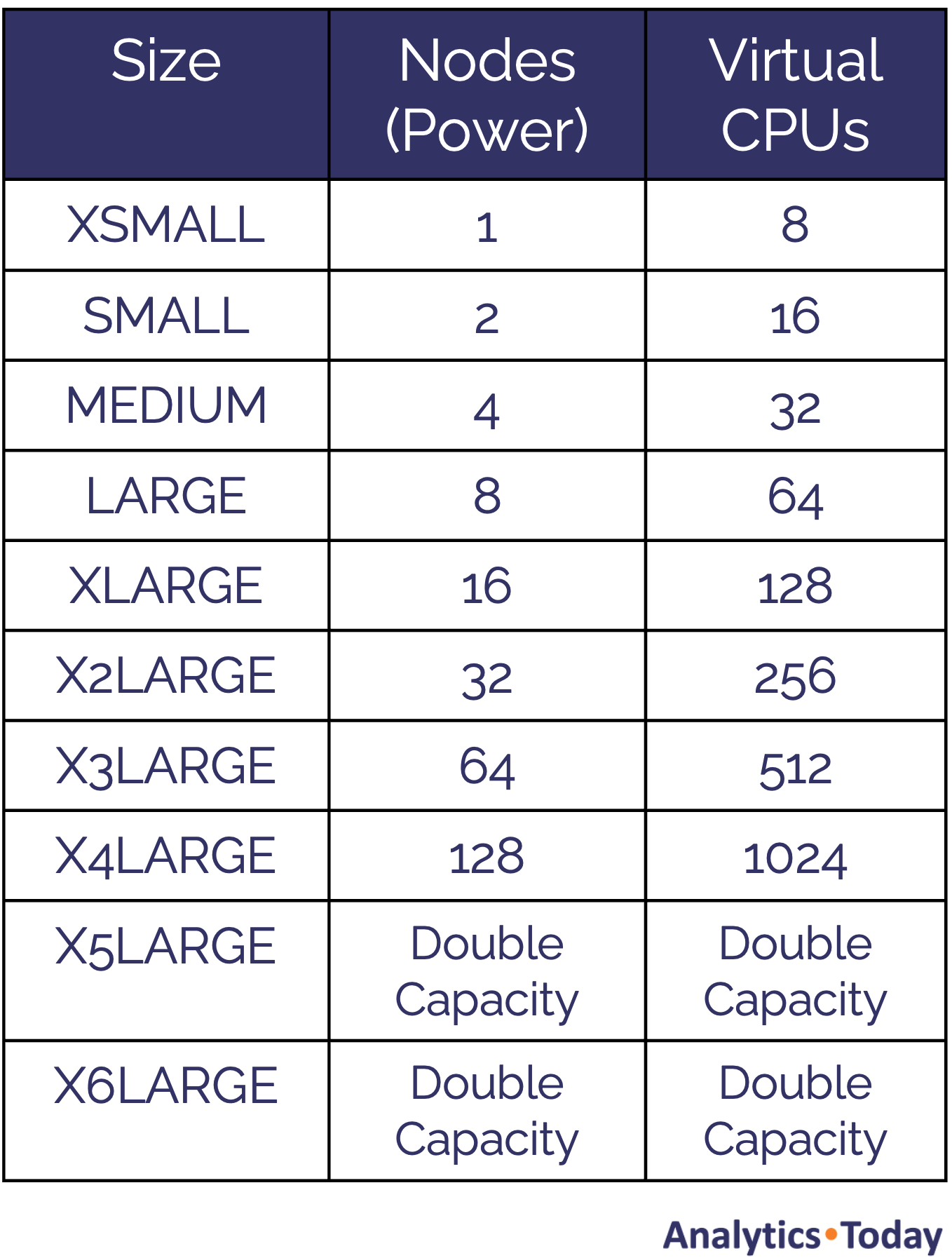
This simple architecture delivers increasingly more powerful hardware whereby each increase in size doubles the potential throughput.
Creating a Virtual Warehouse
The SQL script below shows the command to create a SMALL virtual warehouse that will automatically suspend after 10 minutes and immediately resume when queries are executed.
-- Need SYSADMIN to create warehouses
use role SYSADMIN;
create warehouse PROD_REPORTING with
warehouse_size = SMALL
auto_suspend = 600
auto_resume = true
initially_suspended = true
comment = 'PROD Reporting Warehouse';
Once created, use the following command to select a virtual warehouse:
use warehouse PROD_REPORTING;
Any SQL statements executed from this point will run on the named virtual warehouse. Using this method, different teams can be provided their dedicated hardware, and it’s possible to set a default warehouse for each user.
Snowflake Warehouse - Separation of workloads

Snowflake Logical Architecture
The diagram above illustrates how different groups of users can be allocated a dedicated virtual warehouse. This means ETL processes can continuously load and execute complex transformation procedures on separate warehouses, without impacting finance reports or data scientists running terabyte-sized queries.
Virtual Warehouse Management
On traditional database systems, queries begin to slow down as the workload reaches 100% of capacity. However, Snowflake automatically estimates the resources needed for each query, and as the workload approaches 100%, each new query is suspended in a queue.
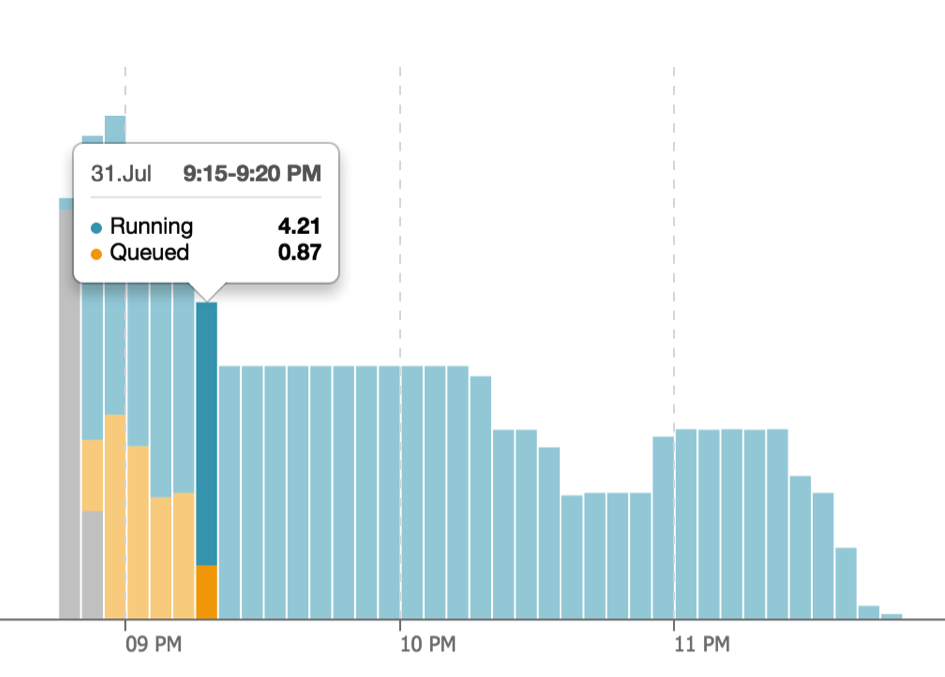
The screenshot above illustrates how as the workload increases, Snowflake temporarily queues the queries until there is sufficient capacity to execute them. Using this method means the average query time is always consistent, as there are options available to resolve the situation automatically.
Scaling Up to Process Large Data Volumes
The diagram below illustrates one potential solution to resolving a queuing problem by increasing the size of the virtual warehouse which typically doubles the performance of subsequently executed queries.

The diagram above shows queries running on a SMALL virtual warehouse, which has been adjusted on-the-fly by the DBA to resize it to a MEDIUM warehouse. The SQL below illustrates how easy this is.
alter warehouse PROD_REPORTING set warehouse_size = MEDIUM;
The command above immediately allocates a MEDIUM sized warehouse with four database servers, and any queries which were queued on the SMALL warehouse are immediately started on the new hardware. Any queries which are already running will run to completion, after which the SMALL warehouse will be automatically suspended.
This means it's possible to adjust the size of the virtual warehouse on the production system on-the-fly without any interruption of service.
Scale Out to Maximise Concurrency
For situations where the virtual warehouse is overloaded with very long-running SQL, scaling up the warehouse will help as queries will run faster. However, if an increasing number of connections causes it, it may be more sensible to scale out rather than scale-up.
The diagram above illustrates the alternative approach whereby as the number of concurrent SQL statements increases, Snowflake can automatically allocate additional same size clusters to cope with increasing demand.
As additional queries are executed, further clusters are added, and when these are no longer needed, they are automatically suspended to save credits.
This technique was successfully deployed by Deliveroo to handle concurrent queries from up to 1,500 data analysts with fantastic performance. The SQL to configure a virtual warehouse is listed below.
alter warehouse PROD_REPORTING set
warehouse_size = MEDIUM
min_cluster_count = 1
max_cluster_count = 5
scaling_policy = ‘STANDARD’;
The diagram below illustrates how Snowflake automatically allocates additional clusters throughout the day depending upon the workload, and then automatically suspends them when no longer needed. Once configured, the entire process runs automatically.
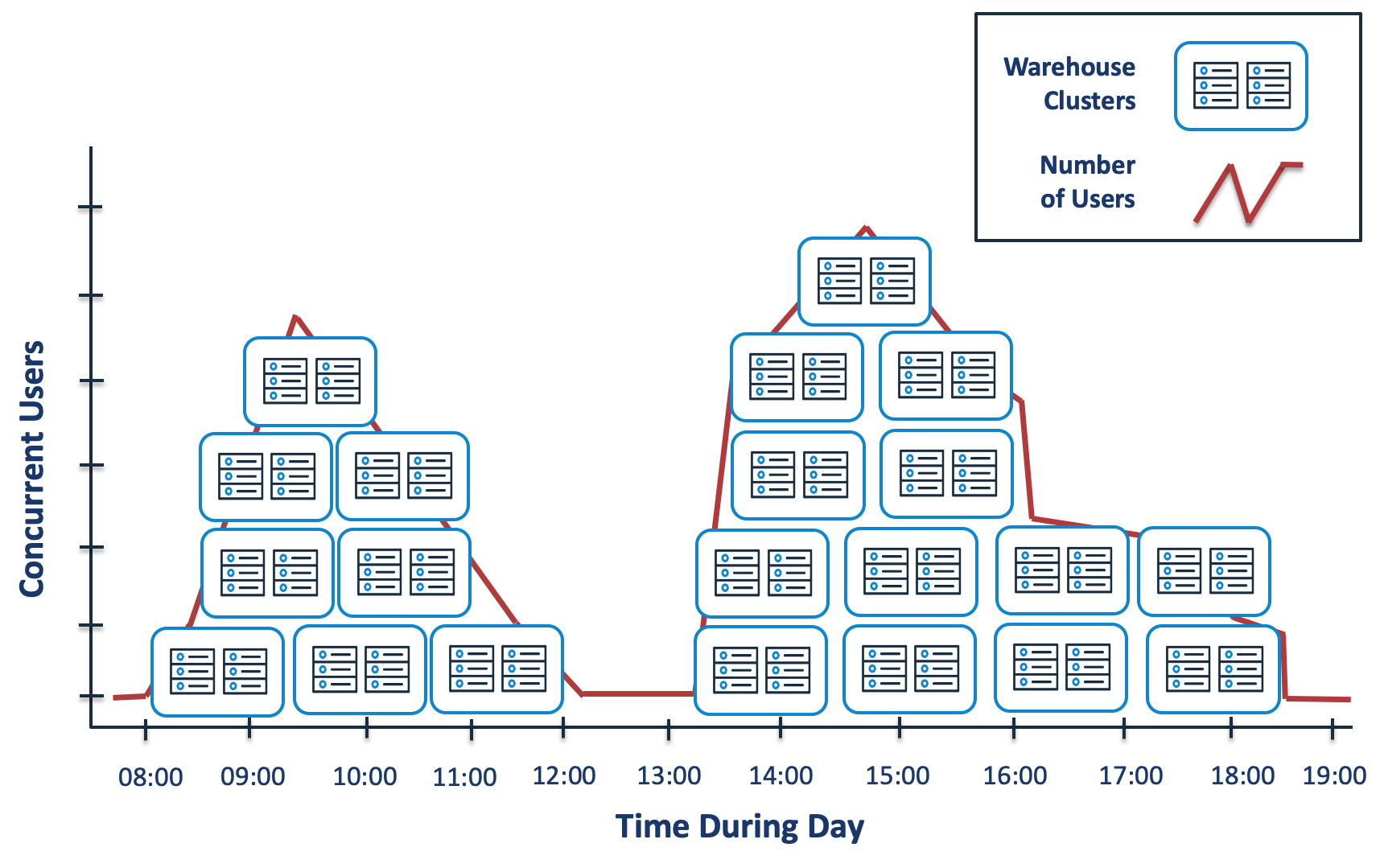
The diagram above shows how at 08:00 no clusters are allocated, but this quickly grows to four as additional users run queries. When the workload subsides, the clusters are transparently suspended, and rise again after lunch. When all SQL has been completed, the cluster transparently suspends after the predefined AUTO SUSPEND period.
Benchmarking a Virtual Warehouse
To demonstrate the power of different-sized virtual warehouses, I repeatedly executed the following SQL query and adjusted the virtual warehouse size.
create or replace table lineitem as
select *
from snowflake_sample_data.tpch_sf10000.lineitem;
The above SQL copies a table holding over 60 billion rows of data in nearly two terabytes of storage, which is considerably larger than the biggest table on any Oracle-based data warehouse I’ve ever worked on. Executing a similar sized process on the production system at a tier one investment bank would have taken around 12 hours.
The graph below shows the effect of scaling up the warehouse and the impact upon both elapsed time and the processing rate.

The above graph shows the elapsed time halved at each point from over seven hours on an X-SMALL warehouse to just four minutes on an X4-LARGE. Meanwhile, the data transfer rate went up from around four gigabytes per minute to over 430 GB/Min.
Snowflake Warehouse Cost
The table below shows the Snowflake Credit usage and an estimate of the USD cost per hour, assuming one credit costs $3.00.

Although we’ve assumed a cost of $3.00 per credit, the actual cost will vary depending upon several factors, including the Cloud Provider, the geographical location and any discount negotiated if you’re willing to commit to buying credits up front.
The real insight from the above table is the cost per hour (although actual time is charged per second) doubles at each increase. However, because the throughput doubles at each step, it’s possible to deliver the same results twice as fast for the exact same cost. My article on Snowflake Cost Optimization explains the reasoning behind this in some detail.
Conclusion
Snowflake delivers a unique database architecture that separates compute processing from data storage and supports extreme flexibility. This means it’s possible to deploy an unlimited number of servers to different user groups, each working on their dedicated hardware with zero contention.
Snowflake can elastically adjust the warehouse size up to a larger server (currently over 430 times the throughput), and down again when the power is no longer needed.
To support substantial concurrent workloads, Snowflake can automatically scale out by adding the same size clusters to an existing warehouse and transparently suspending them to save credits when the workload subsides.
Finally, the entire solution is charged on a pay-for-use basis costing as little per hour as a Starbucks Coffee. Unlike other solutions, per-second billing is charged after the first 60 seconds, with automatic suspend and resume to help control cost.
Snowflake delivers a unique proposition for batch and online query workloads, data processing, data sharing, and real-time data pipelines. You can try it yourself for free for an entire month with $400 of credits and demonstrate it for yourself.
I honestly believe you will be amazed.
Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below, and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.
Disclaimer: The opinions expressed on this site are entirely my own and will not necessarily reflect those of my employer.

John A. Ryan