
Top 10 Strategies for Snowflake Cost Optimization

Having worked at Snowflake for nearly five years, I’ve seen a lot of customers make avoidable but understandable mistakes and waste huge amounts of money. In this article I’ll explain my top 10 tips to optimize snowflake costs and ensure you get the absolute maximum out of this amazing technology.
It is first sensible to explain some of the underlying concepts.
Snowflake Costs
Before attempting to manage your costs you need to understand the unique Snowflake architecture and underlying concepts.
The diagram below illustrates the Snowflake 3-Tier Architecture which consists of three largely independent hardware layers.

Snowflake 3-Tier Architecture
The Snowflake Architecture is made up of the following components:
Cloud Services: Which accepts SQL statements and manages the overall system. Compute is billed per-second but the first 10% of cloud based Snowflake Credit Cost costs are free.
Virtual Warehouses: Also incur Snowflake credit costs which account for about 80-90% of all Snowflake cost and are where most SQL queries are executed. The warehouse cost model is explained below.
Snowflake Storage: Which is a fixed storage cost per terabyte per month, and not a major concern.
Of the three areas, the Virtual Warehouse Cost is the most significant, although there are additional potential costs from:
Serverless Features: For example, Snowpipe, Automatic Clustering, Serverless Tasks and Database Replication. These tend to be billed by the second.
Cross Region Transfer Costs: When data is transferred across Snowflake Accounts in different Regions, the Cloud Provider may charge (per gigabyte) for data transferred across Region or Cloud boundary.
However, as the Virtual Warehouse Cost is the most important, we’ll focus on that.
What is a Snowflake Virtual Warehouse?
A Snowflake Virtual Warehouse is a cluster of one or more servers (nodes) which act as a cluster – effectively behaving like a single machine. A single node is itself a virtual machine which currently consists of eight CPUs, gigabytes of memory and Local Storage (SSD) as illustrated in the diagram below.
Data can be read in parallel from Remote Storage provided by Cloud provider and all local storage is transient – cleared when the warehouse is suspended.
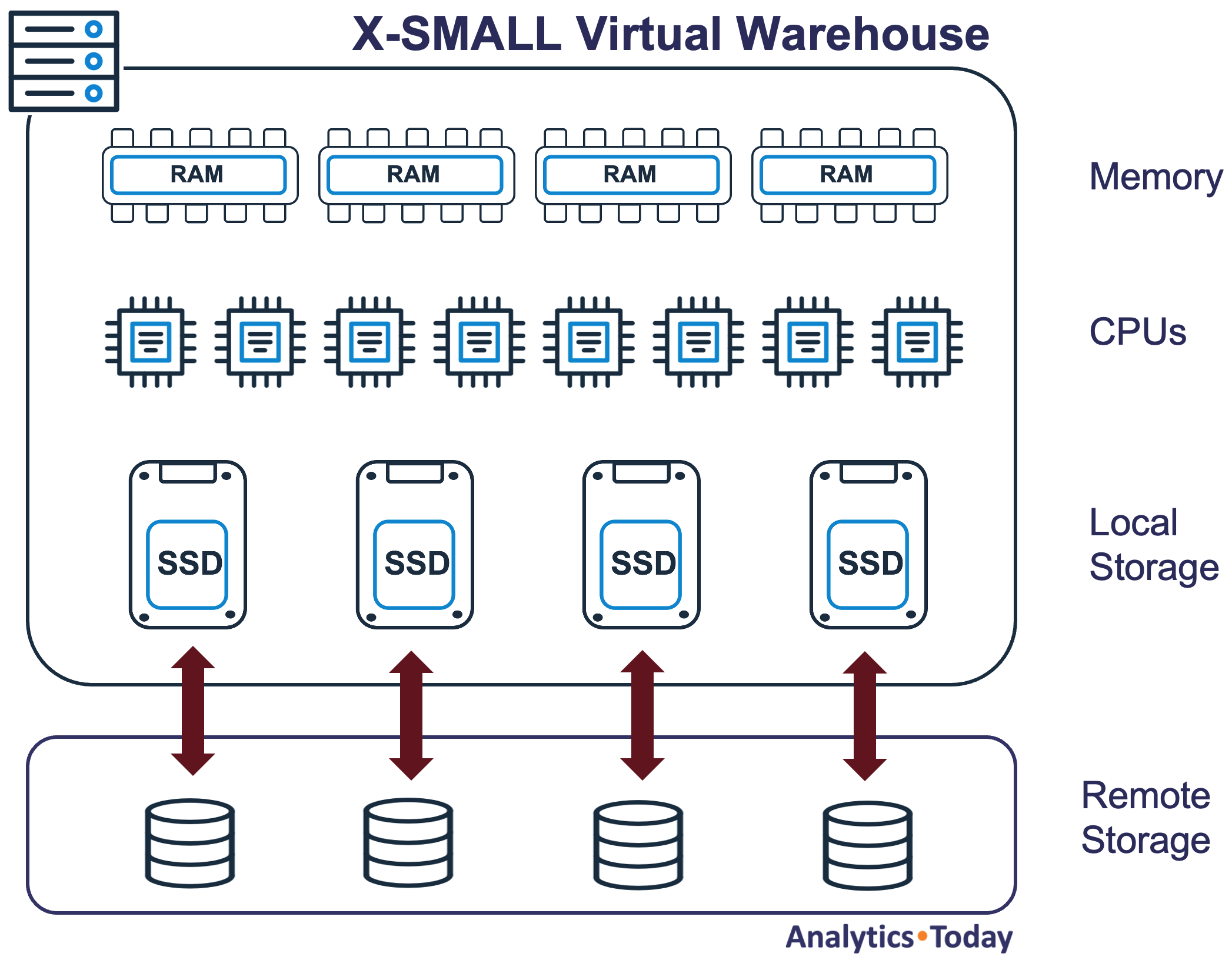
Snowflake Virtual Warehouse
Snowflake Cost by Warehouse Sizes
Identifying the correct Snowflake warehouse size is one of the most important aspects to control Snowflake credit costs. Rather than providing CPU clock speeds and memory size, Snowflake Warehouses are sized in simple T-Shirt sizes ranging from XSMALL to X6LARGE. An XSMALL warehouse consists of a single node, and each increase doubles the number of nodes available and therefore the potential throughput (and associated credit cost) are illustrated in the table below.

Snowflake Credit Cost By Warehouse Size
As you can see, it gets increasingly expensive to run larger warehouses, but don’t fall into the trap of thinking you shouldn’t run large warehouses because of the cost. Each time the T-Shirt size is increased the throughput is also doubled. This means, in most cases you can normally get the same work done twice as fast for the same Snowflake Credit Cost.
How Snowflake Executes Queries
The diagram below illustrates how Snowflake executes queries in parallel across all the available nodes which make up the cluster.
When a user submits a SQL statement for execution, Snowflake uses tiny amounts of metadata held in the Cloud Services layer to identify which micro-partitions hold the actual data on Cloud Storage. It then automatically distributes the metadata to each of the Nodes in the Virtual Warehouse and each Node fetches data in parallel to compute the results which will be returned to the user.
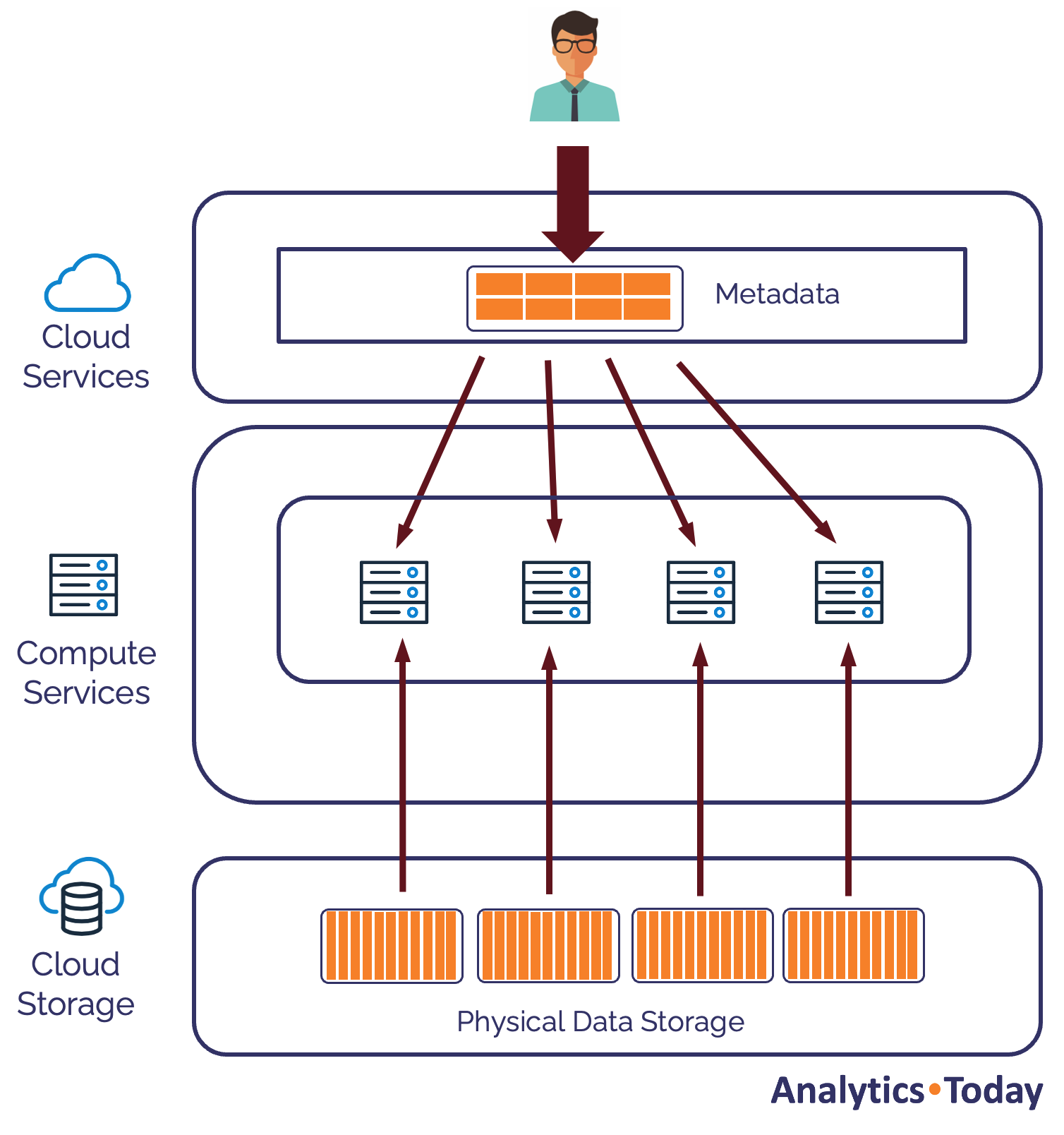
Snowflake Query Execution
Using this method, as the Virtual Warehouse T-Shirt size is increased, queries which process gigabytes of data can be scaled up to execute across even more nodes and reduce query elapsed times from hours to minutes.
Benchmarking Snowflake Warehouse Cost
To demonstrate the effect of Snowflake warehouse cost, we executed the following query on varying sizes of warehouse from X-SMALL to X6LARGE, and recorded the elapsed time at each step. The query involves copying 1.3TB of data, a total of 28.8 billion rows.
insert into store_sales as select * from snowflake_sample_data.tpcds_sf10tcl.store_sales;
The table below shows the elapsed time was reduced from around four hours on an XSMALL warehouse to just 60 seconds on an X6LARGE.
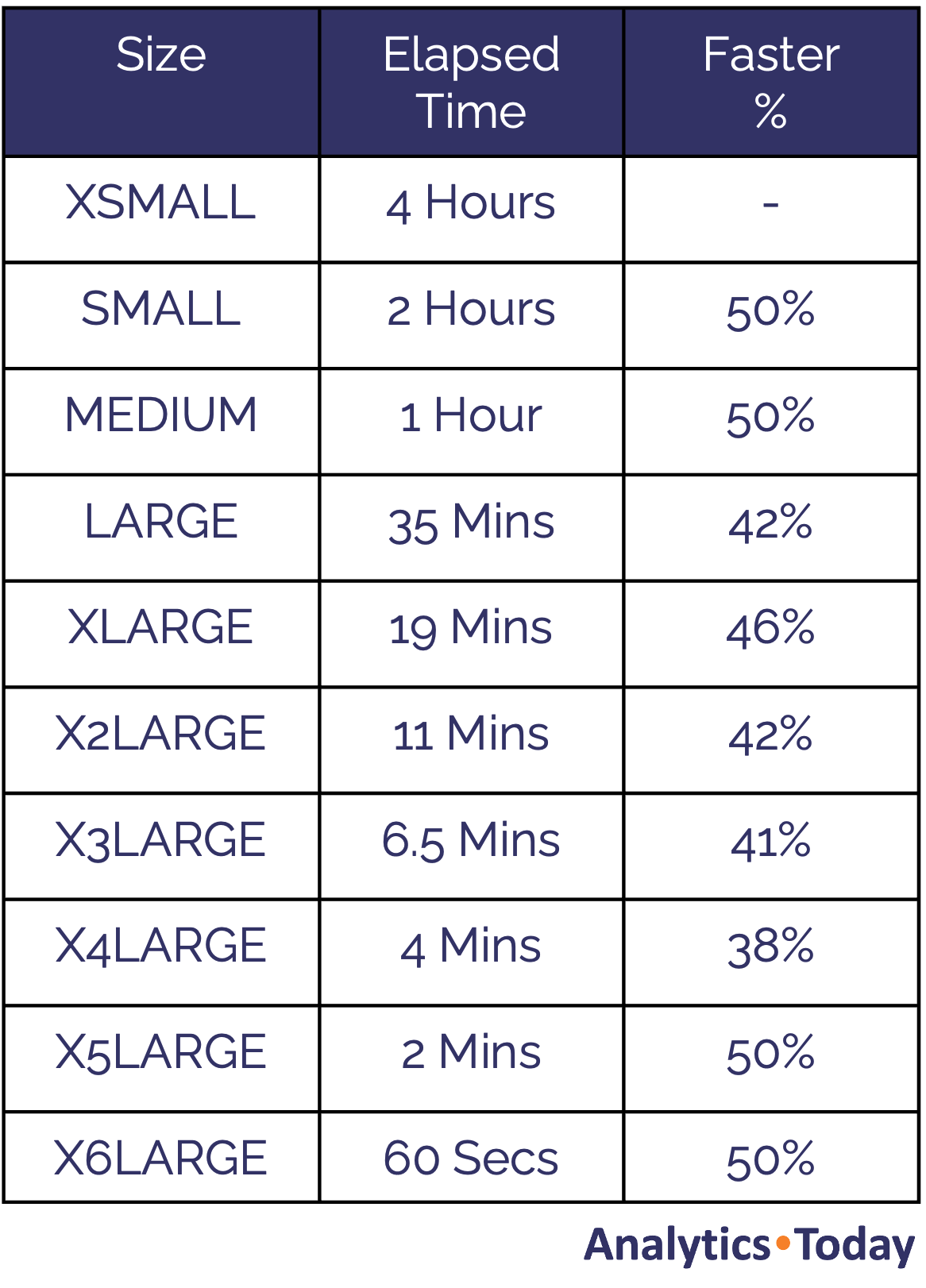
While the query performance times are in themselves impressive, the most important statistic in the table above is not the elapsed time but the improvement at each step.
One of the most important insights about Snowflake is faster queries can result in the same or reduced cost. Effectively this means you can get the same work done much faster for the exact same cost. This is only possible because Snowflake charge on a per-second basis, and warehouses are automatically suspended when idle.
Take the benchmark run on an XSMALL warehouse which took 4 hours. Assuming a credit rate of $3.00, this means the query cost $12.00 to complete.
When run on a SMALL warehouse in just 2 hours at double the rate ($6.00 per hour), the query again cost $12.00. Finally, it completed in just 60 minutes on a MEDIUM size warehouse, again at a cost of $12.00.
This rule holds true as long as the query elapsed time is reduced by 50% (sometimes even more) at each step. To be clear, we can normally expect performance to improve as the warehouse size is increased, but only when the improvement is 50% or more is it cost effective to run queries on the larger cluster.
The diagram below illustrates this effect which shows that each increase in T-Shirt size improving the elapsed time of the query.

The above graph does, however, include another insight. It explains the underlying reason why queries run faster on a larger warehouse.
It would be sensible to assume that because we’re running queries on a larger warehouse, we are improving individual query speed. However, as we increase the warehouse size, the data is distributed across more nodes, increasing the throughput, not the execution speed of each query. While this may improve the overall performance of the task, it means that for any given workload, we will eventually experience diminishing performance improvements as we increase warehouse size.
To put this another way, as we double the warehouse size, we should expect overall workload performance to double at each step. However, we cannot expect performance to continue to double infinitely as; eventually, we hit a point where there is insufficient data volume to keep all the CPUs busy. At this point, increasing warehouse size will reduce the elapsed time by less than 50%, and it’s only worth continuing to scale up if we prioritize performance over cost efficiency.
This is most noticeable on very short, fast queries that return in a few seconds. While these may execute faster when moved from an XSMALL to a SMALL warehouse, they are not necessarily cost-effective unless they run at least twice as fast (a 50% reduction in elapsed time).
This doesn’t mean running queries on larger warehouses is bad practice, but it highlights the direct cost/benefit when choosing warehouse size. Take, for example, the benchmark query above. Assuming $3.00 per credit, this costs $12.00 to complete on an XSMALL warehouse in four hours but just $25.60 on an X6LARGE in around 60 seconds. The decision is purely a matter of prioritizing elapsed time over cost. If the additional cost is worth the improvement in performance, then it makes sense to run the largest warehouse available.
Remember, however, this particular query size costs the same on a MEDIUM warehouse as an XSMALL warehouse but completes 400% faster in 60 minutes instead of four hours. This leads to the first and most critical strategy for cost optimization. You should size your warehouse depending on the size of the query workload and increase warehouse size until you no longer experience a 50% elapsed time reduction.
Maximizing Snowflake Query Throughput
As I have indicated in Top 3 Snowflake Performance Tuning Tactics, scaling up to a larger warehouse is not the only option to maximize throughput on batch transformation jobs. The diagram below illustrates the typical way in many transformation jobs are executed serially.

Serial Query Execution
The diagram shows that as each SQL job is completed on a warehouse, the next job in the sequence is started until all steps are completed. While this made sense using an on-premises system which has fixed-size hardware (as it prevents the machine from being overloaded), it is not sensible on Snowflake.
Unlike traditional databases, as queries are submitted, Snowflake estimates the effort needed to complete the task. If there are insufficient resources available, the query is queued. This prevents the warehouse from becoming overloaded as the option is available to automatically add additional (same size) clusters to the warehouse to scale out automatically. Using this “multi-cluster” approach allows Snowflake to automatically add compute resources to a warehouse as needed and automatically suspend them when no longer needed.

Snowflake Concurrent Workloads
The diagram above illustrates how the multi-cluster feature can be used to automatically add or remove additional SMALL clusters to an existing warehouse as the workload changes during the day. This is typically used for situations where the number of concurrent users on the system varies, for example on Monday morning or during month end. However, this can also be used to maximize throughput for batch transformation jobs.
The diagram below illustrates how we can use the multi-cluster feature to maximize throughput on large transformation jobs. In this example, we use Apache Airflow to submit multiple parallel tasks on the same virtual warehouse. When Snowflake detects the warehouse is becoming overloaded, the Snowflake multi-cluster feature automatically deploys additional clusters to execute the queries which would otherwise be queued waiting for resources.

Snowflake Parallel Transform Jobs
Best of all, as the workload subsides, Snowflake will automatically scale back the clusters to reduce costs, and eventually, the entire warehouse will be suspended. This means you are billed only for the compute time actually used and can get the overall task completed more quickly without the risk of increased cost.
The SQL snippet below illustrates the command to configure a warehouse to automatically scale out to three clusters.
-- Create a multi-cluster warehouse for batch processing
create or replace warehouse batch_vwh with
warehouse_size = SMALL
min_cluster_count = 1
max_cluster_count = 3
scaling_policy = economy
auto_suspend = 30;
Setting the SCALING_POLICY to ECONOMY also helps optimize snowflake warehouse cost by ensuring additional clusters are not allocated unless at least six minutes of work are queued up. This configuration favours throughput over minimizing individual query latency and ensures warehouses are fully loaded.
Controlling Snowflake Credit Costs
After performing a Snowflake cost optimization exercise, carefully selecting the warehouse size and tuning the multi-cluster option, there are additional steps to avoid runaway compute cost. These include setting a statement timeout for queries and creating a Snowflake Resource Monitor.
Snowflake Statement Timeout in Seconds
One of the most significant risks of running SQL on a pay-for-use basis is the risk of a bad query taking hours to complete on a vast warehouse and running up a huge bill. For example, a query that (by accident) includes a cartesian join could spend many credits before it was spotted and killed.
Indeed I had one customer where the DBA was busy trying to finish work on a Friday afternoon and set a query running on an X3LARGE warehouse. The query ran over the entire weekend and clocked up a bill of over $12,000 because there was no Statement Timeout setting on the warehouse.
There is a simple way to prevent this. The SQL statement below sets a limit in query elapsed time (in seconds) for a given warehouse:
alter warehouse batch_vwh set statement_timeout_in_seconds = 10800; -- 10,800 = 3 hours
This sets a maximum time limit on any individual query, after which it will be automatically terminated.
It is, however, sensible to set this timeout based on the warehouse size and, therefore, potential overspending risk. For example, if a query were to run for eight hours on an XSMALL warehouse, this would cost just $24. However, the same query running on an X6LARGE warehouse for eight hours would rack up a bill of over $12,000, assuming $3 per credit.
The challenge in setting a Snowflake statement timeout is that the warehouse cost varies depending on the size, and that makes it difficult to set a realistic elapsed time limit for every warehouse.
One approach is to choose a balance between realistic query duration in hours and acceptable maximum cost. For example, the table below shows the STATEMENT TIMEOUT IN SECONDS for a range of warehouse sizes and the maximum potential cost.

Snowflake Statement Timeout in Seconds
Using this method allows a query to run up to eight hours long on warehouse sizes up to XLARGE. As the warehouse size increases towards the X6LARGE, the maximum allowable run time is reduced to limit the overspending risk.
It was simple to build this using a spreadsheet to calculate the maximum cost for each warehouse size based on elapsed time. Using this method, you can determine acceptable risk for each warehouse size, which determines the statement timeout.
Snowflake Resource Monitors
While the STATEMENT TIMEOUT IN SECONDS protects against a single rogue query taking many hours to run, it won’t protect against a range of other issues which could lead to a significant unexpected credit spend.
create warehouse test_wh with warehouse_size = ‘X4LARGE’ auto_suspend = 0 min_cluster_count = 10 max_cluster_count = 10;
Take, for example, the above SQL statement that a Snowflake customer recently executed. Since the default Snowflake behaviour is to automatically resume the warehouse when a query is executed, this warehouse billed at a rate of $89,280 per day (at $3 per credit) and clocked up a bill of over $120,000 before it was stopped.
The problem is, a MIN_CLUSTER_COUNT of ten automatically starts up ten X4LARGE clusters at 124 credits per cluster or 1,240 credits per hour. However, the AUTO_SUSPEND of zero means it won’t automatically suspend even when there are no queries running. That means it continued to spend nearly $4,000 per hour until manually suspended.
The way to avoid this is to deploy a Snowflake Resource Monitor on every warehouse. The code below shows the SQL needed to both create the Resource Monitor and assign it to the warehouse.
use role accountadmin;
create or replace resource monitor batch_wh_mon with
credit_quota = 48
triggers on 80 percent do notify
on 100 percent do suspend
on 110 percent do suspend_immediate;
create or replace warehouse batch_wh with
warehouse_size = 'MEDIUM'
auto_suspend = 30
resource_monitor = batch_wh_mon
statement_timeout_in_seconds = 28800; -- 3 hours
In this case, we allow the warehouse to spend a maximum of 48 credits per day which on a MEDIUM size warehouse is the equivalent of running for a total of 12 hours per day.
Again, the spend limit should be adjusted according to the warehouse size to optimize snowflake spend.
Top Tips for Snowflake credit cost optimization
Given the extensive insights above, the top tips to optimize warehouse spend include:
Size warehouses depending upon the size of workloads. Be aware queries should run twice as fast on a larger warehouse but stop increasing warehouse size when the elapsed time improvements drops below 50%.
Submit multiple SQL jobs in parallel in a different connection running on a shared batch transformation warehouse to maximize throughput.
For warehouses designed to run lower priority batch jobs set the MAX_CLUSTER_COUNT = 5 and SCALING_POLICY = ‘ECONOMY’ to balance the need to maximize throughput with optimizing compute cost.
For end-user warehouses where performance is a priority set the MAX_CLUSTER_COUNT = 5 and SCALING_POLICY = ‘STANDARD’. This will automatically allocate additional clusters as the concurrent workload increases. However, set the MAX_CLUSTER_COUNT to the smallest number possible while controlling the time spent queuing. With a SCALING POLICY of STANDARD, avoid setting the MAX_CLUSTER_COUNT = 10 (or higher) unless maximizing performance is a much higher priority than controlling cost.
Be aware that queued queries on a batch transformation warehouse are a good sign. Although it extends the SQL elapsed time, it indicates the warehouse is being fully utilized. Provided jobs are completed within the required time, queuing is a positive measure of cost optimization.
Never set the AUTO_SUSPEND to zero unless you are confident you are aware of the potential risks of continuous spending and take steps to suspend warehouses when not needed.
Set a STATEMENT TIMEOUT IN SECONDS for every warehouse based on the warehouse size to limit the risk of overspending on an individual query.
Create a Snowflake Resource Monitor on every warehouse based on size to limit overspending on the entire warehouse.
Be aware that 70% of all Snowflake compute cost is the result of automated jobs. This means a huge proportion of cost is the result of transformation jobs and this should be the priority to optimize Snowflake warehouse cost.
Be aware of the non-functional requirements of the system. The priority for transformation jobs is to maximize throughput while also controlling credit spend whereas the priority for end user queries is often to maximize performance of individual queries and the credit spend tends to be less important. This often means the warehouse configuration is different for transformation and end-user warehouses.
Connect
Connect on LinkedIn and Twitter and I’ll notify you of new articles.
Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.

John A. Ryan