
Snowflake Accounts, Databases and Schemas: Best Practices

Source: Volker Meyer: Pexels
This article explains the best practices for Snowflake databases, schemas, and naming conventions. It explains what options you have for accounts (single, dual, or multiple), a naming convention for databases and schemas, and proposes a sensible data architecture to deploy your data warehouse.
Although the Snowflake database is incredibly easy to use, there are some excellent best practices around the deployment of Snowflake Account, Databases, Schemas. Get it wrong, and you’ll struggle to get the best out of Snowflake. Get it right, and your project has the opportunity to fly.
Account, Database and Schemas and Environments
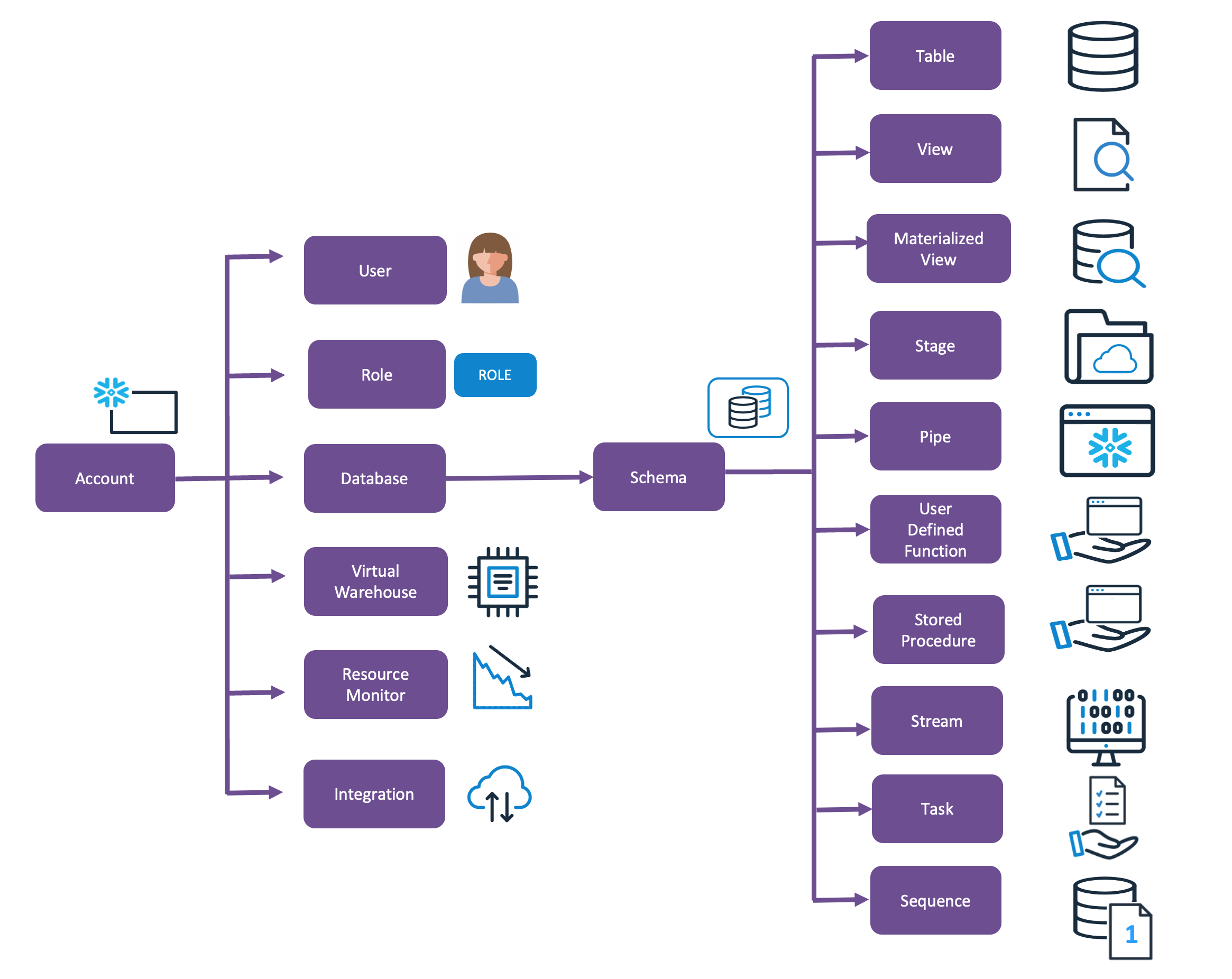
Before describing the best practice, it’s helpful to understand the database hierarchy within a Snowflake deployment. Snowflake is accessed via one or more independent Accounts with each identified by a unique URL.
Within each Snowflake Account, the user can deploy an unlimited number of Databases, and within each database, an almost unlimited number of schemas to hold tables, views, and materialized views.

Unlike other database systems (eg. Oracle), a Snowflake Database is an entirely logical construct, and there is no performance impact when querying tables across Accounts (within the same region), Databases, or Schemas. These are purely designed to organize the analytics data platform.
In summary, within a Snowflake Account, you should create one or more Databases and within each database, one or more Schemas. The diagram below illustrates how Snowflake organises objects within an account.
Best Practices: Snowflake Accounts
Probably the first and most important decision you need to make is how many Snowflake accounts to use. The diagram below illustrates a common mistake that mirrors on the on-premise solution, whereby each database environment is deployed to a different Snowflake Account.

While this may work for some very large systems as it maintains strict isolation, it does have the following drawbacks:
Duplicate Management: As each environment is entirely independent, they must each be managed separately, which unnecessarily adds to the DBA workload.
Separate Login: Administrators need a separate login and password across each of the accounts.
Cloning not possible: The most severe drawback, it is not possible to rapidly clone data across accounts, which makes data management between accounts challenging.
Duplicate Storage: As cloning is not possible, data must be physically copied and therefore duplicated across environments.
The diagram below shows the most straightforward solution in terms of data management. In this case, the entire system is deployed to a single account, and Role-Based Access Control (RBAC) used to maintain separation.

The above solution has the advantage that tables, schemas, or even entire databases can be cloned within seconds, which can be used to provide production-quality data for system testing.
The main drawback is the potential to accidentally grant access to a production schema to a non-production role. However, this risk can be eliminated by scripting grants and using a strong naming convention between environments. This could be used (for example) to generate the script to grant PROD_WORKING_READ role to PROD_DATA_ANALYST. As the actual command is generated, it would automatically prevent granting the PROD access to a DEV role.
The benefit of being able to clone an entire database or schema cannot be overstated, and this enables agile data warehouse development.
For situations where the standards mandate a separate account for Production and non-production workloads, the diagram below illustrates a potential solution using dual accounts.

Using the above method involves creating a separate PROD and NON-PROD account to manage the system. This maintains some of the benefits of being able to clone within the NON-PROD account, while also ensuring the PROD system is isolated and needs a separate login on the PROD account.
Best Practices: Naming Conventions
Having decided upon the number of Snowflake Accounts and environments, it’s worth considering the naming conventions. The diagram below illustrates one of the least apparent but significant constraints within Snowflake that within the same Account, every Role, Warehouse, and Database name must be unique.

This is important because regardless of the Snowflake Account deployment strategy, you will find you need to hold multiple environments within the same account, and therefore each Role, Warehouse, and Database name must include a code indicating the environment. For example, PROD, TEST, or DEV.
Naming conventions for schemas must not include the environment name (for reasons which will become evident later), but it may be sensible to prefix schema names to indicate the purpose. For example:
LND – To indicate a landing schema used to hold newly ingested data.
RAW – To indicate a raw staging area
INT – To indicate an integration area where raw data is combined and cleaned before analysis.
MRT – To indicate a data mart holding conformed and cleaned data ready for reporting.
WRK – To indicate workbench schemas, which provide a sandbox for data analysts.
The diagram below illustrates a potential standard data architecture whereby data is loaded from Cloud Storage into a Landing area. At the same time, the raw history is held in the Raw Staging area, and data prepared in the Integration or Workbench schemas and reported from the Marts area.

Best Practices: Snowflake Database References
At first sight, it may seem sensible to deploy each area in the above diagram as a separate database and several schemas within, but this would be a potentially costly mistake. Consider the following SQL used to transfer data from the PROD_RAW to PROD_LND database.
insert into PROD_RAW.google_analytics.campaign select * from PROD_LND.google_analytics.campaign;
The difficulty comes when executing the above code on a UAT or DEV database, in which case the source code needs to be changed to reflect the different environment. Furthermore, any views materialized views or stored procedures referencing a database name must be substituted and rebuilt upon each environment.
As an alternative, consider the following approach.
-- set the context Use database PROD_DWH; -- Execute Insert insert into lnd_google_analytics.campaign select * from lnd_google_analytics.campaign;
An even better solution would be to define a default database for every user. When users move between environments (for example, from DEV to SIT, they simply change their default database and all subsequent queries reference schemas which are exactly the same across each environment.
The following SQL shows the command to set the default database, virtual warehouse and schema in a single step.
alter user jryan set
default_role = UAT_SUPPORT
default_warehouse = UAT_ADHOC
default_namespace = UAT_DB.MAIN; Conclusion
This article briefly describes the way Snowflake structures objects within an Account into a Database and Schemas. It described the main options to deploy accounts including a common mistake of creating one account for each Development, Test and Production environment and summarised the alternative options which include deploying a single account with environments separated using Role Based Access Control and dual accounts. It’s worth noting, the primary driver behind hosting multiple environments on a single account is the ability to clone tables, schemas or even entire databases. This makes it much easier to produce and maintain test data from a production database.
The article went on to describe best practices for Snowflake naming conventions, and the importance of naming the Roles, Virtual Warehouses and Database with a prefix to indicate the environment, and how this naming convention can be used to prefix areas or zones within the database which should be implemented as schemas prefixed by a short code to indicate the type. This means a given zone can hold multiple schemas, with each prefixed by the same code.
Finally, we saw the need to refer to all objects at the schema level, ideally setting a default database for each user, and then switching the database, warehouse and role to move between different environments within the system.
So far, I’ve worked with over 50 Snowflake customers, and find using these simple practices greatly ease the development burden and let you get on with the more challenging subjects, like understanding your data, your requirements and how to get the very best out of Snowflake.

John A. Ryan
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.