
What is the Ideal Cloud Data Warehouse?

Snowflake!
Originally built for data warehousing, Snowflake provides a first class cloud based analytics platform with a fully ACID compliant database and the ability to support near real-time data pipelines along with ELT batch processing and the option to monitize using Secure Data Sharing.
In this article I will explain the main challenges faced by solution architects building a modern analytics platform that provides a resilient database solution to support data warehousing, data lake and business intelligence workloads.
Background
A few years ago I joined a Tier 1 Investment Bank in London as a Datawarehouse Architect and SQL performance tuning expert, and immediately faced one of the biggest challenges of my entire career.
The mission critical multi-terabyte Oracle warehouse system I was responsible for, was struggling to meet the SQL processing demands, and was failing to meet the SLA for both ETL, and Business Intelligence query performance. This became one of the most challenging periods of my entire career.
Analytics Platform Challenges
Reflecting upon my experience, I found myself dealing with (often conflicting) requirements which included:-
Maximising Query Performance: Which means minimising latency, the time taken for end user SQL queries to complete. As most data warehouse architects will testify, end user query performance can always be improved, often falls short of requirements, and analytic query demands are increasingly hard to satisfy.
Maximising Throughput: Typically batch ETL or ELT tasks must complete as quickly as possible which means running multiple processes in parallel to make best use of machine resources. This also applies to CPU intensive maintenance and housekeeping operations including the capture of query optimiser statistics to help deliver efficient query plans.
Maximising Machine Usage: To make efficient use of machine resources, the warehouse should ideally be run at 100% CPU capacity. Clearly this often conflicts with the two priorities above, but running at any less is a waste of CPU resources. Unlike a car, a computer system won’t last any longer if it’s sitting idle most of the time. Indeed, having paid potentially millions of dollars for the hardware, it is imperative that you make the most efficient use of the resources.
“You cannot put CPU in the bank and save it for later. So, if you are running with idle cycles you should be looking for more ways to use it”
To make matters worse most systems have several competing groups:-
Micro-Batch ETL and ELT Processes: Which typically run on a repeating cycle. The machine tends to be overloaded during this time, either at or above 100% capacity in an attempt to process the data as quickly as possible, and deliver new data to the business.
Business Intelligence Reporting: Which tends to be erratic, with load varying between zero and maximum capacity throughout the day. Alternatively, the load profile may follow a regular pattern, for example with additional queries at month or year end, otherwise machine load can vary enormously throughout the day.
Dashboard Queries: Which need very fast (sub-second) performance to refresh online dashboards. Machine load in these cases is extremely unpredictable, but when the capacity is needed, results must be available immediatly.
The chart below illustrates a typical ETL or ELT load profile with repeating batch processes which run the machine at nearly 100% capacity. These tasks typically maximise throughput - to complete as much work as possible in the shortest possible timescale.

This compares markedly to the typical Business Intelligence query profile illustrated below which is much more erratic, and typically needs to maximise individual query performance to deliver insights as quickly as possible.

The most common approach to manage these competing demands involves creating a Workload Management Queue whereby each user group is allocated 50% of machine resources. This places queries in two separate queues, with each limited to a fixed number of concurrent queries or tasks executed in parallel. If there are insufficient resources available, the queries are queued, and when the machine is heavily loaded, they can even be timed out.
The combined profile might look like this:-

While fine in theory, the difficulties with this solution quickly become apparent.
Capped Maximum Usage: As each group is given half the machine resources, the ETL processes which would normally run at 100% CPU are limited to 50%, and the ETL run times are therefore extended. This may well be acceptable, as long as the work completes in a reasonable timeframe, but as additional data sources are identified, there is a constant need to tune and re-tune the system to process an ever increasing workload in the fixed timeframe available.
Built in Inefficiency: Business Intelligence and dashboard query load tends to be highly erratic, but even while running heavy ETL load tasks we need to reserve spare capacity. This means the CPUs are seldom run at maximum capacity. Equally, when both ETL and analytic queries are running, usage can exceed capacity, and this often leads to frustration as elapsed times can vary massively. Conversely batch tasks are limited to 50% capacity, even if there are no online queries being executed, which is wasteful of machine resources.
In conclusion, although it appears to be fair in principle, neither group is fully satisfied, and there’s an on-going tug-of-war for increasingly scarce machine resources. In effect, we have the worst of both worlds.
Performance Tuning Options
Limit Resource Usage: Using increasingly aggressive use of workload management to control the number of concurrent online queries and batch tasks.
Database and Application Tuning: Often the most effective way to improve SQL throughput, this can involve a number of database design techniques including deployment of an aggregate data strategy, building indexes or database or query tuning. This is however, a complex and potentially expensive strategy, and even with a team of highly skilled engineers, it can take months to deliver meaningful results. In my case it took a team of three experts almost a year to completely resolve the performance issues.
Improve the Hardware: Which typically involves the following approach:-
Scale Up: Which involves additional memory, CPUs or faster disk storage or even migrating the entire application to a new, larger machine.
Scale Out: Which is an option for Massively Parallel Processing (MPP) architectures, which involves adding nodes to the existing system.

Traditional SMP Database Architecture
When running on a shared memory architecture, the only realistic option is to scale up the hardware.
The diagram below illustrates this architecture, and the solution involves adding CPUs or memory or migrating to a bigger machine. Like the database and application tuning option described above, this can take months to complete. A typical data warehouse system can have a huge number of incoming and outgoing data feeds, many undocumented, and the preparation, testing and migration process can take considerable time.

Symmetric Multi-processing (SMP) Architecture
Including the time to agree the necessary budget and assemble the team, it took almost a year to migrate a large and complex Oracle data warehouse to a new Exadata platform.
To make matters worse, like building additional lanes on motorways, the workload typically increases to make use of the additional capacity, and a few years down the line the system will need upgrading yet again.
Clearly this is not a sustainable long term strategy.
MPP Database Architecture
The diagram below illustrates the massively parallel processing (MPP) architecture used by many databases and warehouse appliances including Vertica, Teradata and Greenplum. In this solution, it is possible to add additional nodes to an existing cluster which adds both compute and storage resources.

Massively Parallel Processing (MPP) Architecture
While this can be an easier compared to the scale up approach described above it does have the following drawbacks:-
Time to Market: Adding nodes to an existing on-premises MPP system still requires a potentially lengthy ordering, deployment and installation process which can take days or even weeks to complete.
Database Reorganisation: On MPP systems the data is sharded (distributed) across nodes in the cluster which enables parallel query execution. When an additional node is added, often the existing tables need to be reorganised to make use of the additional capacity, and this can be a complex and resource intensive operation, which often impacts system availability. It short it needs down-time which may not be an option in some cases.
Over-capacity: In theory MPP systems are balanced in that adding machines adds both storage and compute resources. However, because these are so closely tied, if storage demands exceed the need for processing capacity, the cost per terabyte can rise disproportionately. This is especially prevalent with the recent move towards a Data Lake solution which can potentially store massive data volumes which are often infrequently accessed, and often relies upon inexpensive storage. Indeed research by Clarity Insights showed a variance as much as 300:1 compared to independent storage solutions. In summary, this means on an MPP system you could be paying for 300 times more compute processing than you actually need, because you are storing petabytes of data.

Snowflake: The Ideal Cloud Analytics Platform.
An ideal analytics platform would be an ACID compliant SQL database. It would consist of multiple independent clusters of machines each running different workloads, and each individually sized to the particular demands of the task in hand. It would be possible to scale up (or down) within seconds, but still quickly extend the data storage independent of compute resources.
Effectively, this would deliver the best of both worlds. The ability to scale up or down on demand (the scale out architecture), while also retaining the ability to add additional clusters to support additional concurrent users, while avoiding any down-time or resource intensive processing resulting from the need to reorganise the database.
The diagram below illustrates the logical architecture of Snowflake, the cloud based data warehouse platform:-
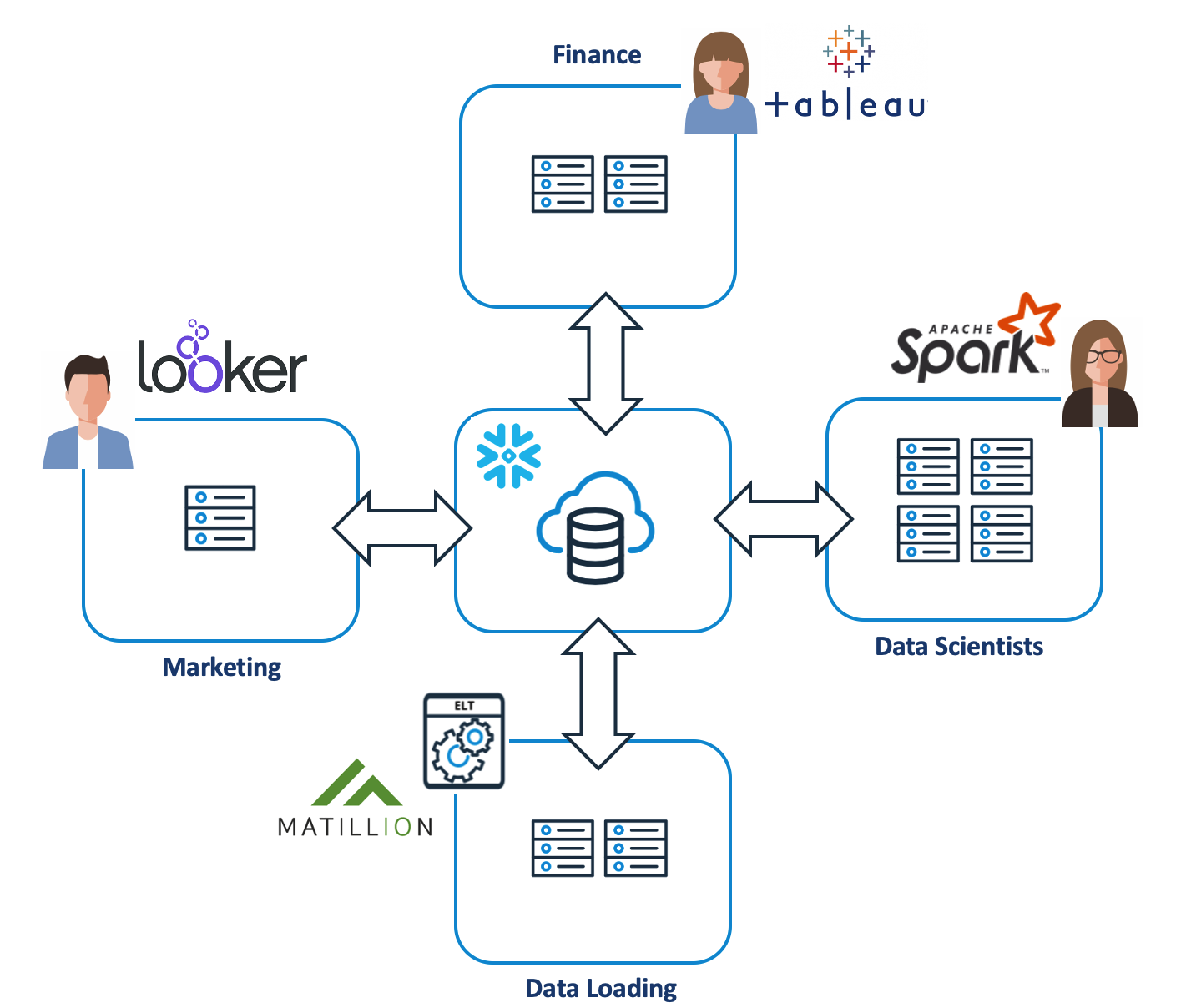
Snowflake Virtual Warehouses - Each workload runs on independent hardware
The Snowflake Datawarehouse deploys multiple independent clusters of compute resources over a shared data pool. Users are allocated a Virtual Warehouse (a cluster of compute resources), on which to run ETL/ELT load processes or Business Intelligence queries. However, unlike the traditional solutions, each virtual warehouse runs completely independently of the others, avoiding the tug of war for machine resources found on almost every other database solution.
The benefits include:-
Fast to Deploy: As the solution is provided as a cloud based service, a database can be deployed within minutes without installing new hardware or even a long term financial commitment.
Complete Flexibility: With the ability to scale up or down within seconds, or even suspend the service when not being used, and compute resources charged on a per-second basis. In multi-cluster mode, if there is a temporary jump in end user query demands, the option exists to automatically start up additional clusters, which are available immediately without any data reorganisation. Once the query workload subsides, the additional resources are transparently suspended, and the entire operation can run without DBA involvement.
Pay Separately for Storage: As storage is charged separately from compute resources (currently as little as $23 per compressed terabyte per month), it is possible to scale up to petabyte sizes, but pay only for the storage and processing power on as as-needed basis. This differs greatly from other MPP solutions like Teradata, Redshift or Vertica where adding nodes adds to both compute and storage at the same time.
Zero Contention: With the ability to allocate multiple clusters of varying sized virtual warehouses to different tasks, there is no contention for compute resources. This would allow ETL/ELT processes to run completely separately from end user queries while also being shielded from the massively unpredictable analytic query demands of data scientists.
Absolute Simplicity: Unlike the legacy database solutions from Oracle, Microsoft and IBM, Snowflake was built from the ground up for modern cloud based analytics. It’s not just an on-premises based solution moved to the cloud, and there is no indexing, partitioning or data sharding go manage. There are also no query plan statistics to capture, and almost no options to tune the system. It just works.

The screen shot above illustrates just how easy it is to adjust the size of a Snowflake cluster. Using T-shirt sizing, the operator can choose to resize the cluster from the current Medium size of 4 nodes to a maximum of 128, and this is normally available within seconds.
All queued or subsequently executed queries are automatically started on the larger cluster, and the operation can be scripted and scheduled using SQL to automatically start a larger cluster before running a large and demanding task.
Performance Challenge Revisited
The charts below illustrate the batch ETL/ELT and business intelligence query profile on the Snowflake datawarehouse. Unlike the traditional approach, the user groups can be deployed on entirely independent clusters, each sized as appropriate. This is simply not possible on most database platforms including the cloud based managed solutions provided by AWS Redshift and Oracle or IBM.

The benefits of this solution include:-
Independent Sizing: Which means processing intensive batch operations can be provisioned on a much larger cluster than the business reporting system. This allows users to right size the solution to the problem, and provide each user group with appropriate compute resources needed. It is also easier to allocate and control budgets on different projects as each virtual warehouse is independently managed and costs accounted for.
Ability to Scale Up/Down: Often the batch or query workload increases on a regular basis, for example at month or financial year end. Normally this would lead to reduced performance leading to delays and frustration, but Snowflake has the option to scale up or down the system to cope with the additional demands. This can be scripted using SQL, and all new queries are automatically started on the larger, more powerful cluster.
Automatic Scale Out: While the number of concurrent ETL/ELT tasks is largely predictable, business intelligence query workloads are often erratic, and during peak periods, it is still possible queries will be queued. To maintain end user performance, the option exists to configure the virtual warehouse to run in multi-cluster mode. Unlike the scale up option described above, this adds additional same size nodes to an existing cluster. Additional nodes are automatically added as query demands exceed the ability of the cluster to cope, and once the peak demand subsides, these can be transparently suspended to manage costs.
“Benchmarks are demonstrating that separate compute and storage can outperform dedicated MPP relational database platforms.”
Conclusion
Just a few years ago, the only options available to scale an analytics or data warehouse platform were by application tuning or migrating to a bigger machine. If you were lucky enough to be running Teradata, Vertica or Greenplum, you might consider extending the existing cluster, but the short term options were limited, and it might take weeks to respond to a increases in demand.
Snowflake has changed the analytics platform landscape by delivering an innovative multi-cluster shared data database system which delivers the flexibility to spin up, suspend or resize MPP clusters to exactly match load requirements.
In addition, because storage and compute a deployed separately, it is possible to independently scale either as storage, or processing as requirements change.
Best of all, you only pay for the compute resources you need, and these are charged on a per-second basis which makes this both a compelling and potentially cost effective solution.
Disclosure: These are my personal opinions and do not necessarily reflect those of my employer.
Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.

John A. Ryan
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.