
When should I use Data Vault?

Data Vault is an innovative data modelling methodology for large scale Data Warehouse platforms. Invented by Dan Linstedt, Data Vault is designed to deliver an Enterprise Data Warehouse while addressing the drawbacks of the normalized (3rd normal form), and Dimensional Modelling techniques. It combines the centralized raw data repository of the Inmon approach with the incremental build advantages of Kimball.
This article summarizes the drawbacks of the 3NF and Dimensional Design approach and lists the advantages and disadvantages of the Data Vault approach. Finally, it includes links to some useful background reading, and aims to answer the question: Should I use Data Vault or another data modelling method?
What Problem is Data Vault trying to solve?
Before summarising the challenges that Data Vault is trying to address, it’s worth considering the alternative data modelling approach and corresponding data architectures. The diagram below shows a potential Enterprise Data Architecture.
Enterprise Data Warehouse
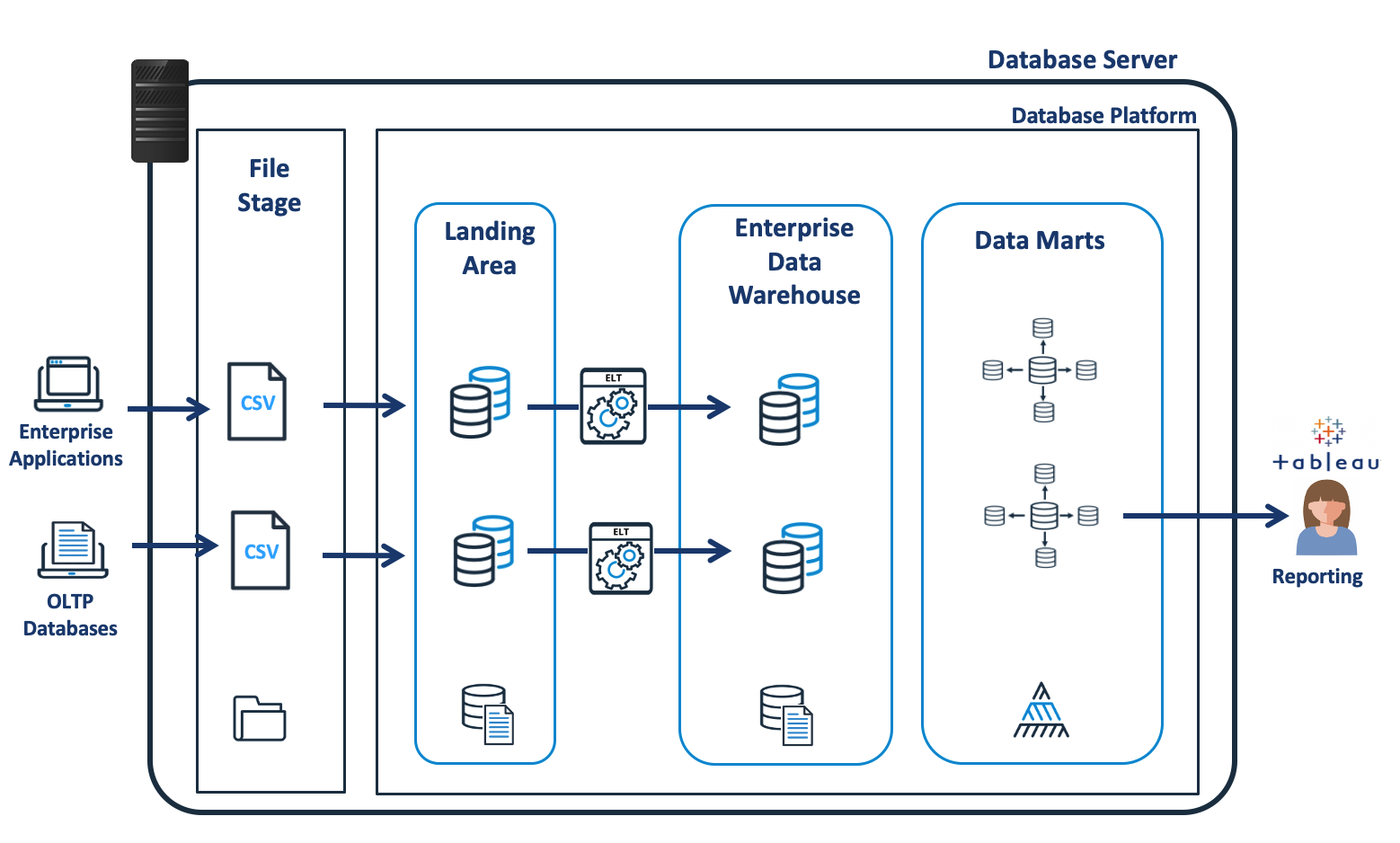
Enterprise Data Warehouse Architecture
With the EDW approach, data is loaded into a transient Landing Area, after which a series of ETL processes are used to load data into a 3rd Normal form enterprise data warehouse. The data is subsequently extracted into dimensional data marts for analysis and reporting.
The most significant disadvantages of this approach include:
Time to Market: The Enterprise Data Warehouse must first integrate data from each of the source systems into a central data repository before it’s available for reporting, which adds time and effort to the project.
Complexity and Skill: A data warehouse may need to integrate data from a hundred sources, and designing an enterprise-wide data model to support a complex business environment is a significant challenge that requires highly skilled data modelling experts.
Lack of Flexibility: A third normal form model tends to model the existing data relationships, which can produce a relatively inflexible solution that needs significant rework as additional sources are added. Worse still, over-zealous data modelling experts often attempt to overcome this by delivering over-complex generic models that are almost impossible to understand.
Dimensional Design Approach
The diagram below illustrates a potential data architecture for a classic Dimensional Data Warehouse design.

Kimball Dimensional Data Warehouse Architecture
The approach above dispenses with the EDW to quickly deliver results to end-users. I used this technique in 2008 at a London based tier one Investment bank to provide credit risk assessments to business users within weeks of starting the project. If we’d waited to build a traditional data warehouse, we’d have gone bankrupt before we’d delivered anything useful.
Initially, the business users were thrilled at the speed of delivery; however, over time, we found many challenges that became increasingly painful to deal with. These included:
1. Increasing code complexity: The ETL code (Extract, Transform, and Load) was becoming so complicated it was no longer manageable. Replacing the ETL tool (Informatica) with Oracle scripts helped, (as we simplified the solution as we went), but that wasn’t the root of the problem. We were trying to restructure the incoming data, deduplicate, clean and conform the data, and apply changing business rules over time. Doing all these steps in a single code base was very hard indeed.
2. Lack of Raw Data: As the landing area was purely transient (deleted and reloaded each time), we had no historical record of raw data. This made it difficult for analysts to discover valuable new data relationships, and the increasing importance of Data Science, which (above all) needs raw data, was simply ignored.
3. Managing History: As we had no history of raw data and only loaded the attributes needed for analysis, it became difficult to back-populate additional data feeds.
4. Lineage was challenging: As both the technical and business logic was implemented in ever-increasing sedimentary layers of source code, it was almost impossible to track the lineage of a data item from the report back to the source system.
The business loved the initial speed of delivery. Howeverl, as time went on, it became increasingly hard to maintain the pace as the solution became increasingly complex, and business rules changed over time.
Data Vault Architecture
The diagram below shows a potential data architecture used by the Data Vault methodology.
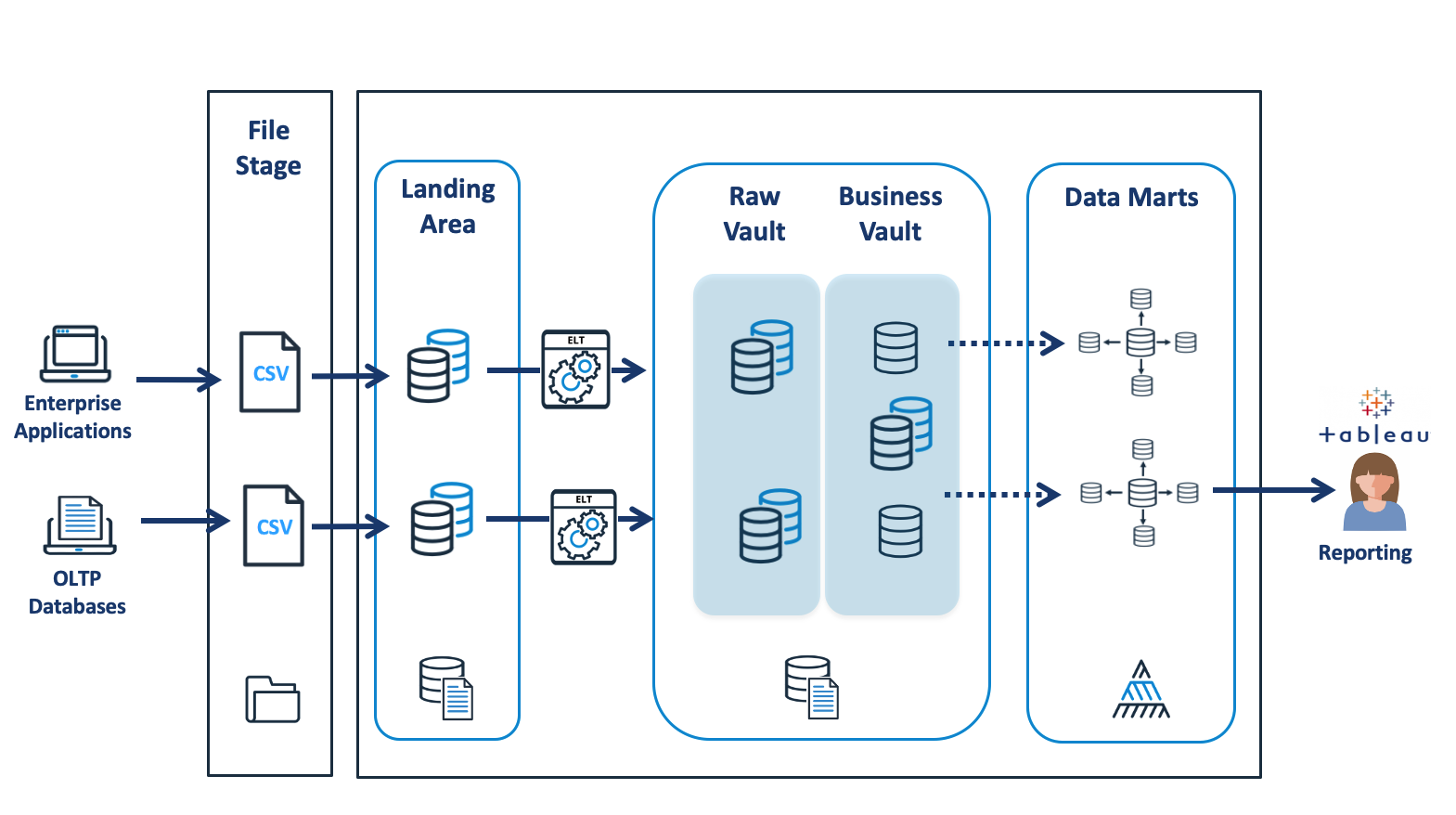
Data Warehouse - Data Vault Architecture
While at first glance, it looks very similar to the Enterprise Data Warehouse architecture above, it has a few significant differences and similarities, which include:
Data Loading: As the data is loaded from the Landing Area into the Raw Data Vault, the process is purely one of restructuring the format (rather than content) of the data. The source data is neither cleaned nor modified, and could be entirely reconstructed without issue.
Separation of Responsibility: The Raw Vault holds the unmodified raw data, and the only processing is entirely technical, to physically restructure the data. The business rules deliver additional tables and rows to extend the Raw Vault with a Business Vault. This means the business rules are both derived from and stored separately from the raw data. This separation of responsibility makes it easier to manage business rule changes over time and reduces overall system complexity.
Business Rules: The results of business rules, including deduplication, conformed results, and even calculations are stored centrally in the Business Vault. This helps avoid duplicate computation and potential inconsistencies when results are calculated for two or more data marts.
Data Marts: Unlike the Kimball method in which calculated results are stored in Fact and Dimension tables in the Data Marts, using the Data Vault approach, the Data Marts are often ephemeral, and are may be implemented as views directly over the Business and Raw Vault. This means they are both easier to modify over time and avoids the risk of inconsistent results. If views don’t provide the necessary level of performance, then the option exists to store results in a table.
The Data Vault Advantages
Data Vault addresses the difficulties inherent in both the 3rd Normal Form Enterprise Data Warehouse and the Dimensional Design approach by combining the best aspects of both in a single hybrid approach. The advantages include:
1. Incremental delivery: While it is sensible to build any Data Warehouse within the context of an overall enterprise model, Data Vault supports entirely incremental delivery. Just like Kimball’s Dimensional Design approach, you can start small and incrementally add additional sources over time.
2. Flexibility: Unlike the 3rd Normal Form modelling approach, which can be inflexible, Data Vault requires no rework when adding additional sources. As Data Vault stores the Raw and Business derived data separately, it supports changes to business rules with ease.
3. Reduced Complexity: As Data Vault is built out in a two-step approach, it separates the technical data restructuring from the application of business rules, which helps isolate these potentially complex stages. Likewise, data cleaning is considered a business rule and can be managed independently of the initial data load effort.
4. Raw Data Included: Recording the raw data in Data Vault means it’s possible to back-populate the presentation area with historical attributes that were not initially made available. If the Data Marts are implemented as views, this can be as simple as adding an additional column to an existing view.
5. Elegantly supports change over time: Similar to the slowly changing dimension in the Kimball approach, Data Vault elegantly supports changes over time. Unlike the pure Dimensional Design, however, Data Vault separates the Raw and Business derived data and supports changes resulting from both the source system and the business rules.
6. Lineage and Audit: As Data Vault includes metadata identifying the source systems, it makes it easier to support data lineage. Unlike the Dimensional Design approach in which data is cleaned before loading, Data Vault changes are always incremental, and results are never lost, which provides an automatic audit trail.
7. High-Performance Parallel Loads: With the introduction of Hash Keys in Data Vault 2.0, data load dependencies are eliminated, which means near real-time data loading is possible in addition to parallel loads of terabytes to petabytes of data.
8. Possible to Automate: While both Entity Relationship Modelling and Dimensional Design require time and experience to build skills, Data Vault tends to easier to automate, and there are several tools (listed below) to help deliver the solution.
The Drawbacks of Data Vault
Data Vault is not the perfect one size fits all solution for every data warehouse, and it does have a few drawbacks that must be considered. These include:
1. The Learning curve: In precisely the same way that 3rd Normal Form, Entity Relationship Modelling, and Dimensional Design are specific skills that take time to master, there is a learning curve with Data Vault. Embarking on a Data Warehouse transformation project comes with significant risks, and adding Data Vault will increase the risk. Make sure you have expert advice and support in addition to training for key individuals.
2. Lots of Joins: A poorly designed Data Vault design will produce a massive number of source system derived tables, but even a well-designed solution multiplies the count of source tables by a factor of 2 or 3. The number of tables and therefore joins can appear unwieldy and lead to complex join conditions. This can, however, be addressed with the correct use of bridge tables in the Business Vault, and as with any solution, it’s a trade-off of apparent complexity and flexibility.
Where to use Data Vault?
Data Vault requires some rigor in delivering good design and sticking to the Data Vault 2.0 principles. Like the Enterprise Data Warehouse, it is designed to integrate data from several data sources and may, therefore, be overkill in some situations.
In summary, if you have a small to medium-sized analytics requirement, with a small (under 10) team of architects, designers, and engineers delivering a solution with data sourced from a few systems, then Data Vault may be inappropriate for your needs.
If, however, you have a large project with 30 or more source systems leading to an enormous data integration challenge and are prepared to take on the skills and rigor of a new methodology, then Data Vault can potentially add massive value to the project.
Other Resources and Tools
The following resources may help evaluate and understand the Data Vault method:
Kent Graziano (certified Data Vault Master) has a summary of Data Vault worth reading.
The Genesee Academy (Training) provides a good introduction to the main principles of Data Vault.
UK Consultancy Data Vault Provide an informative summary of Frequently Asked Questions that address many of the immediate concerns.
Dan Linstedt has a huge number of in-depth articles on the details around Data Vault.
Building a Scalable Data Warehouse with Data Vault 2.0 – is the reference book by Dan Linstedt.
The Elephant in the Fridge – is an accessible introduction to Data Vault.
Although these should not be considered in any way a recommendation, here’s a shortlist of the tools which can help to automate the delivery of Data Vault.
Conclusion
As on-premise data warehouse projects are moved to the cloud, an increasing number of enterprises are rethinking how the Data Warehouse is architected. The move from multiple independent on-premise data silos to a modern cloud based solution is a once-in-a-career opportunity to integrate data from across the entire enterprise in a single, consistent repository.
If that’s the challenge you face, then Data Vault may well help to deliver the solution.
Follow me
On LinkedIn and Twitter and I’ll notify you of new articles.
Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.

John A. Ryan