
Top Snowflake ETL Best Practices for Data Engineers
Article updated: 4-Jun-2023

Photo by Danil Shostak on Unsplash
10-Minute Read.
In this article, we will describe the data Snowflake transformation landscape, explain the steps and the options available, and summarize the data engineering best practices learned from over 50 engagements with Snowflake customers.
What are Snowflake Transformation and ETL?
ETL or ELT (Extract Transform and Load) are often used interchangeably as a short code for data engineering. For the purposes of this article, Data Engineering is the process of transforming raw data into useful information to facilitate data-driven business decisions. The main steps include data loading, which involves ingesting raw data followed by cleaning, restructuring, enriching the data by combining additional attributes, and finally, preparing it for consumption by end users.
ETL and Transformation tend to be used interchangeably, although the transformation task is a subset of the overall ETL pipeline.
Snowflake ETL in Practice
The diagram below illustrates the Snowflake ETL data flow to build complex data engineering pipelines. There are several components, and you may not use all of them on your project, but they are based on my experience with Snowflake customers over the past five years.
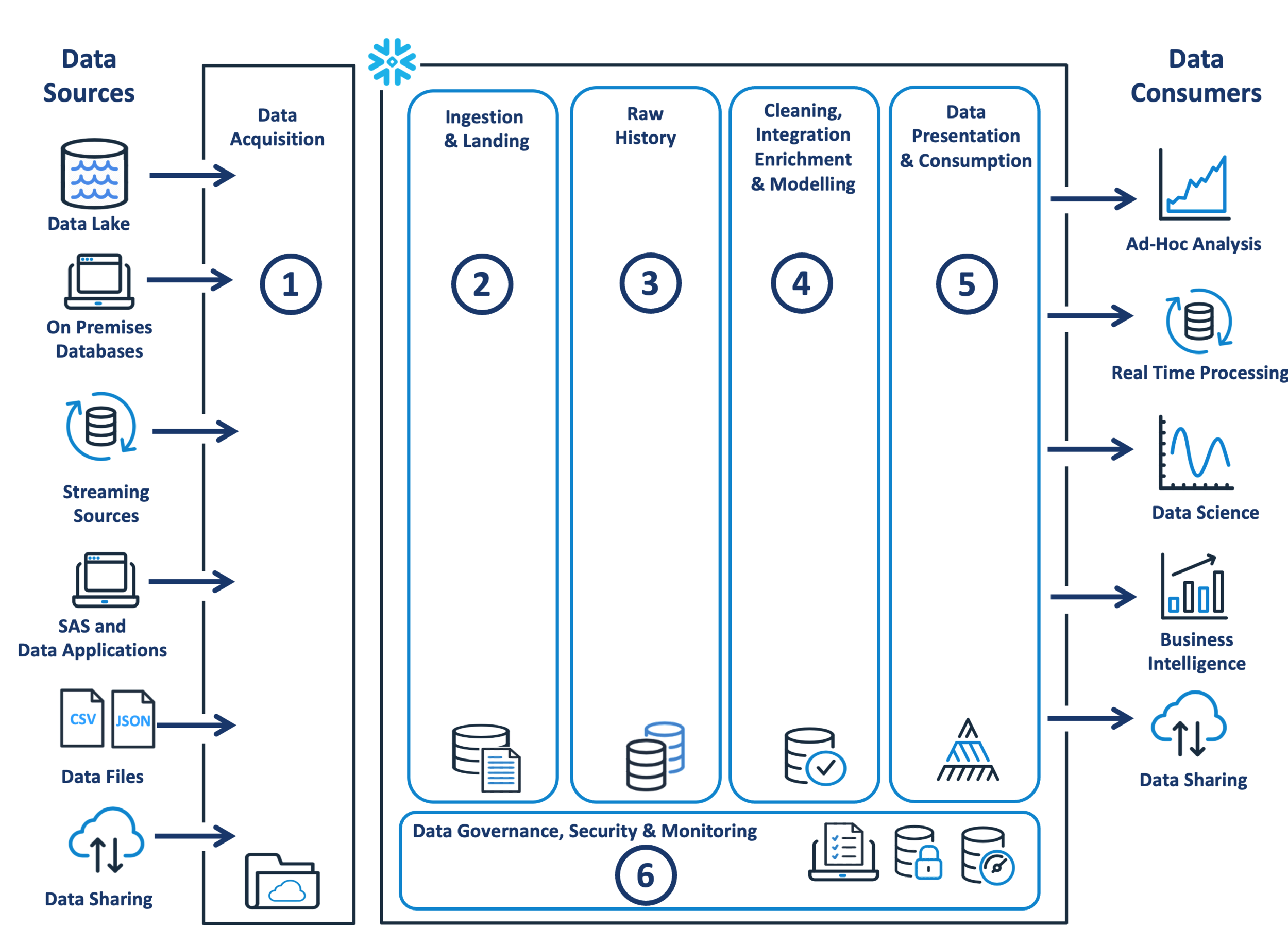
The diagram above shows the data sources, which may include:
Data Lakes: Some Snowflake customers already have an existing cloud-based Data Lake, which acts as an enterprise-wide store of raw historical data that feeds both the data warehouse and machine learning initiatives. Typically, data is stored in S3, Azure or GCP cloud storage in CSV, JSON or Parquet format.
On-Premises Databases: These include both operational databases, which generate data, and existing on-premise data warehouses, which are in the process of being migrated to Snowflake. These can (for example) include billing systems and ERP systems used to manage business operations.
Streaming Sources: Unlike on-premises databases, where the data is relatively static, streaming data sources constantly feed in new data. This can include data from Internet of Things (IoT) devices, Web Logs, and Social Media sources.
SaaS and Data Applications: This includes existing Software as a Service (SaaS) systems, for example, ServiceNow and Salesforce, which have Snowflake connectors and other cloud-based applications.
Data Files: Include data provided from either cloud or on-premises systems in various file formats, including CSV, JSON, Parquet, Avro and ORC, which Snowflake can store and query natively.
Data Sharing: Refers to the ability for Snowflake to expose read-only access to data on other Snowflake accounts seamlessly. The Snowflake Data Exchange or Marketplace provides instant access to data across all major cloud platforms (Google, AWS or Microsoft) and global regions. This can enrich existing information with additional externally sourced data without physically copying the data.
In common with all analytics platforms, the data engineering phases include:
Data Staging: This involves capturing and storing raw data files on cloud storage, including Amazon S3, Azure Blob or GCP storage.
Data Loading: This involves loading the data into a Snowflake table, which can be cleaned and transformed. It's good practice to initially load data to a transient table, balancing the need for speed, resilience, simplicity, and reduced storage cost.
Raw History: Unless the data is sourced from a raw data lake, retaining the raw data history is good practice to support machine learning and data re-processing as needed.
Data Integration: This is cleaning and enriching data with additional attributes and restructuring and integrating the data. It's usually good practice to use temporary or transient tables to store intermediate results during the transformation process, with the final results stored in Snowflake permanent tables.
Data Presentation and Consumption: Whereas the Data Integration area may hold data in the 3rd Normal Form or Data Vault, storing data ready for consumption in a Kimball Dimensional Design or denormalised tables as needed usually is good practice. This area can also include a layer of views acting as a semantic layer to insulate users from the underlying table design.
Data Governance, Security and Monitoring: Refers to managing access to the data, including Role Based Access Control and handling sensitive data using Dynamic Data Masking and Row Level Security. This also supports monitoring Snowflake usage and cost to ensure the platform operates efficiently.
Finally, the data consumers can include dashboards and ad-hoc analysis, real-time processing and Machine Learning, business intelligence or data sharing.
Snowflake Data Loading Options
The diagram below illustrates the options available to stage and load data into a landing table - the first step in the Snowflake data engineering pipeline.
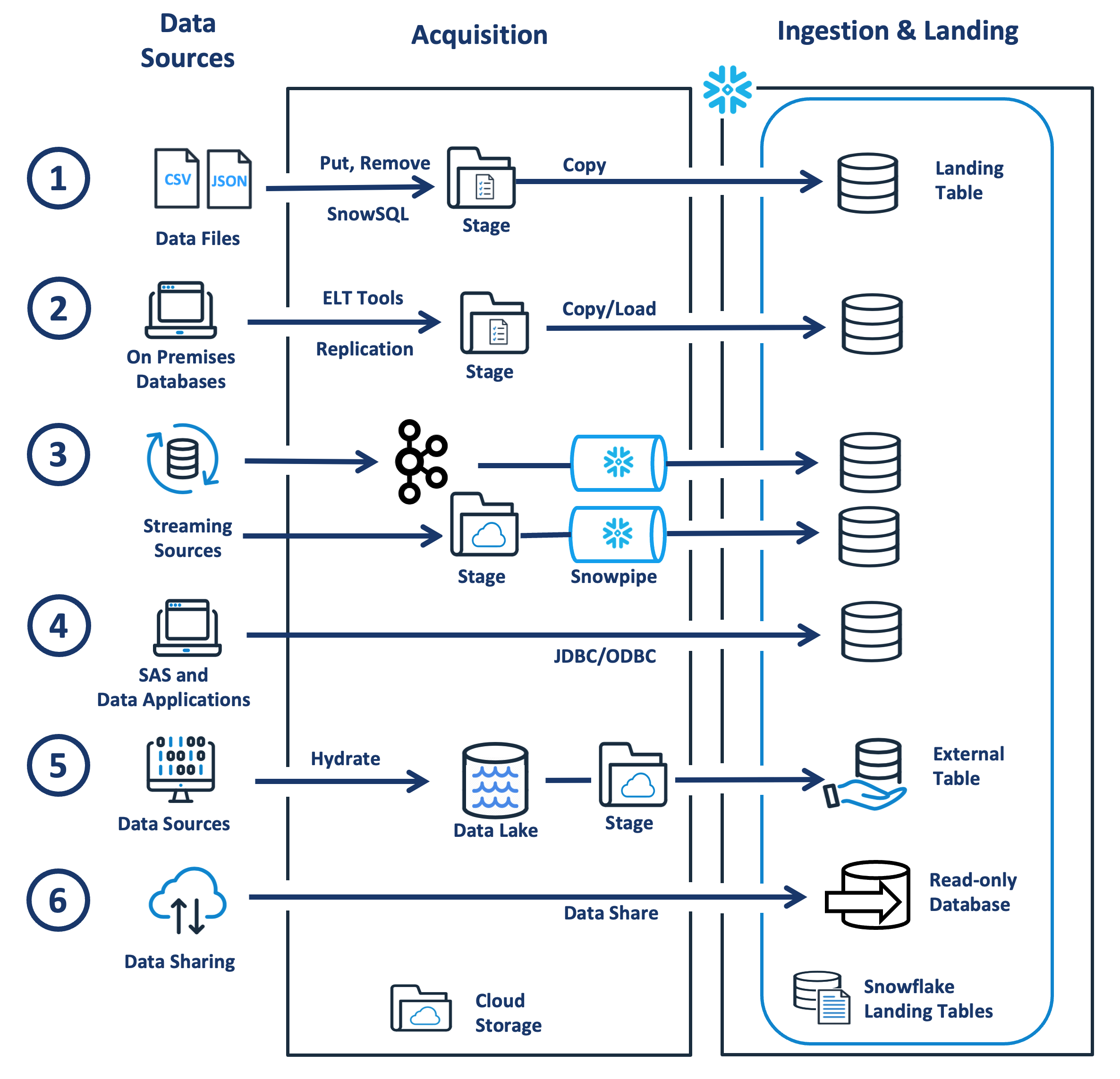
As the diagram above shows, Snowflake supports a wide range of use cases, including:
Data File Loading: This is the most common and highly efficient data loading method in Snowflake. This involves using SnowSQL to rapidly execute SQL commands to load data into a landing table. Using this technique, it's possible to load terabytes of data quickly, which can be performed on a batch or micro-batch basis. Once the data files are held in a cloud stage (EG. S3 buckets), the COPY command can load the data into Snowflake. This is the most common method for most large-volume batch data loading tasks, and it's usually good practice to size data files at around 100-250 megabytes of compressed data, optionally breaking up huge data files appropriately.
Replication from Premises Databases: Snowflake supports a range of data replication and ETL tools, including HVR, Stitch, Fivetran and Qlik Replicate, which seamlessly replicate changes from operational or legacy warehouse systems with zero impact upon the source system. Equally, a vast range of data integration tools include Snowflake support and direct replication from other database platforms, which can be used to extract and load data. Equally, some customers write their data extraction routines and use the Data File Loading and COPY technique described above.
Data Streaming: Options to stream data into Snowflake include using the Snowflake Kafka Connector to automatically ingest data directly from a Kafka topic, as demonstrated by this remarkable video demonstration. Unlike the COPY command, which needs a virtual warehouse, Snowpipe is an entirely serverless process, and Snowflake manages the operation completely, scaling out the compute resources as needed. Equally, the option exists to trigger Snowpipe to load data files automatically when they arrive on cloud storage.
Inserts using JDBC and ODBC: Although not the most efficient way to bulk load data into Snowflake (using COPY or Snowpipe is always faster and more efficient), the Snowflake JDBC and ODBC connectors are available in addition to a range of Connectors and Drivers, including Python, Node.js and Go.
Ingestion from a Data Lake: While Snowflake can host a Data Lake, customers with an existing investment in a cloud data lake can use Snowflake External Tables to provide a transparent interface to data in the lake. From a Snowflake perspective, the data appears to be held in a read-only table, but the data is transparently read from the underlying files on cloud storage.
Data Sharing: The Data Exchange provides a seamless way to share data globally for customers with multiple Snowflake deployments. Using the underlying Snowflake Data Sharing technology, customers can query and join data in real time from various sources without copying. Existing in-house data can also be enriched with additional attributes from externally sourced data using the Snowflake Data Marketplace.
You may notice a consistent design pattern in the above scenarios as follows:
1. Stage the data: Loading data files to a Snowflake file stage.
2. Load the data: Into a Snowflake table.
Once the data has landed in Snowflake, it can be transformed using the techniques described below. In some cases, Snowflake has made the entire process appear seamless, for example, using the Kafka Connector or Snowpipe, but the underlying design pattern is the same.
Snowflake Transformation Options
Having ingested the data into a Snowflake landing table, several tools are available to clean, enrich and transform the data, illustrated in the diagram below.

The options available to transform data include the following:
Using ETL Tools: This often has the advantage of leveraging the existing skill set within the data engineering team, and Snowflake supports a wide range of data integration tools. It is best practice when using these to ensure they follow the pushdown principle, in which the ETL tool executes SQL, which is pushed down to Snowflake to gain maximum benefit from the scale-up architecture.
Using Stored Procedures: Besides the JavaScript API, Snowflake supports a procedural language, Snowflake Scripting. This includes support for loops, cursors and dynamic SQL similar to Oracle's PL/SQL. When combined with the additional power of External Functions and Java User Defined Functions, these features can be used to build and execute sophisticated transformation logic within Snowflake. However, the best practice for delivering highly scalable data transformation solutions is to avoid row-by-row processing. Instead, use SQL statements to execute set processing executing functions as needed for complex logic. Organise the steps using the procedural code and External and Java UDFs for complex calculations.
Incremental Views: A pattern commonly found on systems migrated from Teradata and uses a series of views built upon views to build a real-time transformation pipeline. It is good practice to break complex views into smaller steps and write intermediate results to transient tables, as this makes it easier to test and debug and, in many cases, can lead to significant performance improvements.
Streams & Tasks: Snowflake Streams provide a compelling but straightforward way of implementing simple change data capture (CDC) within Snowflake. It is good practice to combine Streams and Snowflake Tasks on data acquired for near real-time processing. Effectively, the Stream keeps a pointer in the data to record the already processed results, and the Task provides scheduling to periodically transform the newly arrived data. Previously, it was necessary to allocate a suitably sized virtual warehouse to execute the task. Still, the recent release of the Serverless Compute option further simplifies the task and means Snowflake automatically manages the compute resources, scaling up or out as needed.
Spark and Java on Snowflake: Using the recently released Snowpark API, Data Engineers and Data Scientists who would previously load data into a Databricks Cluster to execute SparkSQL jobs can now develop using Visual Studio, IntelliJ, SBT, Scala and Jupyter notebooks with Spark DataFrames automatically translated and directed as Snowflake SQL. Combined with the ability to execute Java UDFs, this provides powerful options to transform data in Snowflake using your preferred development environment without the additional cost and complexity of supporting external clusters.
The data transformation patterns described above show the most common methods; however, each Snowflake component can be combined seamlessly. For example, although Streams and Tasks are commonly used together, they can each be used independently to build a bespoke transformation pipeline and combined with materialised views to deliver highly scalable and performant solutions.
“If the only tool you have is a hammer, you tend to see every problem as a nail”. Abraham Maslow.
Conclusion: Snowflake ETL and Data Engineering Best Practices
The article above summarises several options and highlights some of the best data engineering practices on Snowflake. The critical lessons learned from working with Snowflake customers include the following:
Follow the standard ingestion pattern: This involves the multi-stage process of staging the data files in cloud storage and loading files to a Snowflake transient table before transforming the data and storing it in a permanent table. Breaking the overall strategy into independent stages makes it easier to orchestrate and test.
Retain history of raw data: Unless your data is sourced from a raw data lake, it makes sense to keep the raw data history which should ideally be stored using the VARIANT data type to benefit from automatic schema evolution. This means you can truncate and re-process data if bugs are found in the transformation pipeline and provide an excellent raw data source for Data Scientists. While you may not yet have any machine learning requirements, it's almost sure you will, if not now, then in the coming years. Remember that Snowflake data storage is remarkably cheap, unlike on-premises solutions.
Use multiple data models: On-premises data storage was so expensive it was not feasible to store numerous copies of data, each using a different data model to match the need. However, using Snowflake, storing raw data history in either structured or variant format, cleaning and conformed data in the 3rd Normal Form or using a Data Vault model makes sense. Finally, data is ready for consumption in a Kimball Dimensional Data model. Each data model has unique benefits, and storing the results of intermediate steps has huge architectural benefits, not least the ability to reload and reprocess the data in case of mistakes.
Use the right tool: As the quote above implies, if you are only aware of one ELT tool or method, you'll almost certainly misuse it at some point. The decision about the ELT tool should be based upon a range of factors, including the existing skill set in the team, whether you need rapid near real-time delivery, and whether you're doing a once-off data load or regular repeating loads. Be aware that Snowflake can natively handle a range of file formats, including Avro, Parquet, ORC, JSON and CSV. There is extensive guidance on loading data into Snowflake on the online documentation.
Use COPY or SNOWPIPE to load data: Around 80% of data loaded into a data warehouse is either ingested using a regular batch process or, increasingly, immediately in near real-time after the data files arrive. By far, the fastest, most cost-efficient way to load data is using COPY and SNOWPIPE, so avoid the temptation to use other methods (for example, queries against external tables) for regular data loads. Effectively, this is another example of using the right tool.
Avoid JDBC or ODBC for regular large data loads: Another right tool recommendation. While a JDBC or ODBC interface may be acceptable to load a few megabytes of data, these interfaces will not scale to the massive throughput of COPY and SNOWPIPE. Use them by all means, but not for sizeable regular data loads.
Avoid Scanning Files: Using the COPY command to ingest data, use partitioned staged data files. This reduces the effort of scanning large numbers of data files in cloud storage.
Choose a suitable Virtual Warehouse size: Don’t assume an X6-LARGE warehouse will load huge data files faster than an X-SMALL. Each physical file is loaded sequentially on a single CPU, and it is more sensible to load most loads on an X-SMALL warehouse. Consider splitting massive data files into 100-250MB chunks and loading them on a larger (perhaps MEDIUM size) warehouse.
Ensure 3rd party tools push down: ETL tools like Ab Initio, Talend and Informatica were initially designed to extract data from source systems into an ETL server, transform the data and write them to the warehouse. As Snowflake can draw upon massive on-demand compute resources and automatically scale out, it makes no sense to use and have data copied to an external server. Instead, use the ELT (Extract, Load and Transform) method, and ensure the tools generate and execute SQL statements on Snowflake to maximise throughput and reduce costs. Excellent examples include DBT and Matillion.
Transform data in Steps: A common mistake by inexperienced data engineers is to write massive SQL statements that join, summarise and process lots of tables in the mistaken belief this is an efficient way of working. In reality, the code becomes over-complex, challenging to maintain, and, worst still, often performs poorly. Instead, break the transformation ETL pipeline into multiple steps and write results to intermediate transient tables. This makes it easier to test intermediate results, simplifies the code and often produces simple SQL code that will almost certainly run faster.
Use Transient tables for intermediate results: During a complex ETL pipeline, write intermediate results to a transient table which may be truncated before the next load. This reduces the time-travel storage to just one day and avoids an additional seven days of fail-safe storage. By all means, use temporary tables if sensible, but the option to check the results of intermediate steps in a complex ELT pipeline is often helpful.
Avoid row-by-row processing: As described in the article on Snowflake Query Tuning, Snowflake is designed to ingest, process and analyse billions of rows at fantastic speed. This is often referred to as set-at-a-time processing. However, people tend to think about row-by-row processing, which sometimes leads to programming loops that fetch and update rows one at a time. Remember that row-by-row processing is the most significant way to kill query performance. Use SQL statements to process all table entries simultaneously and avoid row-by-row processing at all costs.
Use Query Tags: When you start any multi-step transformation task, set the session query tag using: ALTER SESSION SET QUERY_TAG = 'XXXXXX' and at the end, ALTER SESSION UNSET QUERY_TAG. This stamps every SQL statement until reset with an identifier and is invaluable to System Administrators. As every SQL statement (and QUERY_TAG) is recorded in the QUERY_HISTORY view, you can track the job performance over time. This can quickly identify when a task change has resulted in poor performance, identify inefficient transformation jobs or indicate when a job would be better executed on a larger or smaller warehouse.
Keep it Simple: Probably the best indicator of an experienced data engineer is their value on simplicity. You can always make a job 10% faster, generic, or more elegant, and it may be beneficial, but it always helps to simplify a solution. Simple solutions are easier to understand, easier to diagnose problems and are therefore easier to maintain. Around 50% of the performance challenges I face are difficult to resolve because the solution is a single, monolithic complex block of code. To resolve this, I first break down the key components into smaller steps and only then identify the root cause.
Conclusion
Snowflake supports many tools and components to ingest and transform data, and each is designed for a specific use case. These include traditional batch ingestion and processing, continuous data streaming and exploration on a data lake.
It's easy to get lost in the array of options and, worse still, to use an inappropriate tool for the task. I hope the description above and the best practices help you deliver faster, more efficient and more straightforward data pipelines.
Can you Help?
Do you think this article was helpful? Can you explain why in the comments below?
I’m writing a book, “Snowflake: Best Practices”, and I’m interested in your opinion on what to include. What’s important to you? I'd appreciate your thoughts.
You may also find this article interesting.

Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.

John A. Ryan